1.说话人分类常用算法
说话人分类是说话人识别中的一大主题,目前已经发展了很多方法,这些方法大致可以分为两类: (1)基于概率分布的高复杂度的精确分类算法,如高斯混合模型(Gaussian Mixture Model,GMM)、隐马尔科夫 模型(Hidden Markov Model,HMM)和支持向量机(Support Vector Machine,SVM)模型; (2)基于模板的低复杂度的分类算法,如向量量化方法(Vector Quantization,VQ)。 第一类说话人分类算法能取得不错的效果,但他们的高复杂度使得进行说话人识别需要很长时间,不适合于实时应用。 而第二类说话人匪类算法虽然复杂度低,但当系统中说话人的人数增加时,识别性能下降得很快。
Wu Junwen,Zhang Xuegong提出了一种基于PCA的分类器(即主成分子空间(Principal Component Subspace,PCS)分类器), 作为一种线性分类器,其复杂度低于以上第一类算法,又表现出很好的分类能力。另外,我们还可以根据截断误差子空间来构造分类器, 称为TES(Truncation Error Subspace)分类器。这两种分类器反映了主成分分析方法的两个方面,结合两种分类器可得到混合分类器, 称其为P&T分类器。
2.主成分分析的分类依据
对语音信号进行特征提取后,将得到的数据进行主成分分析,经过训练确定主成分的个数m和经过主成分变换的特征数据(即主成分 子空间),同时也可得到截断误差子空间,主成分子空间或截断误差子空间即可作为描述说话人特征的模型。
PCS分类器的基本思路是,对于一个待分类样本$X$,将它向数据集中每个说话人模型(即PCS)投影,即 计算$U_{k}^{T}(X-\mu _{k})$,其中$U_{k}$为数据集中第$k$个说话人的模型,$\mu _{k})$为每个模型的中心向量,定义投影 量所保留的原向量的方差为:
TES分类器与PCS分类器类似,只是说话人模型是用TES来表示的,对应的说话人模型相似度的度量标准为:
而对应的决策规则为:
在使用P&T分类器时要注意,在计算f(k),g(k)之前,应先对PCS和TES进行归一化,以免某一个值太大而影响了另一个值的作用。
3.主成分分类器应用于说话人识别
根据说话人识别任务的特点,基于PCA的分类器需要解决两个问题: (1)训练说话人模型; (2)对测试音进行鉴别。
说话人鉴别的训练过程,就是训练每个说话人的模型参数,在此以PCS分类器为例进行说明。PCS分类器的模型参数由两部分组成, 即主成分主方向数m和主成分子空间$PCS=[U1,U2,…,Um]$。关于主成分的计算在前面的文章中讲过,就不在赘述,这里重点说说主方向 数确定的方法。为了使得PCS分类器的分类效果最好,我们可以选用少量的说话人以及他们的少量的测试语音,组成确定阈值的“验证 集(validation set)”,变动主方向数$m$,选取使得识别率最好时的主方向数$m$作为参数。为简单起见,我们令所有说话人的主成分 方向数取相同的值。
测试音鉴别:设数据库中共有M个说话人模型,${X(n)|n=1,2,…,N}$为某个测试语音上提取的特征向量序列,则模型相似度度量标准为:
4.实验结果
分别在无噪语料库YOHO和有噪语料库PHONE做实验,得到如下结果:
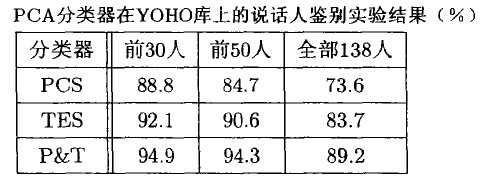
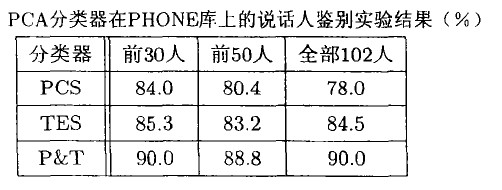
5.复杂度分析
P&T分类器的复杂度 模型训练阶段: $PTtrain = N*d+N*d+d*d*N+4/3d^{3}+O(d^{2})+O(dlogd) = O(N*d^{2})+O(d^{3})$ 模型测试阶段: $PTtest=M*Ntest*P*d+M*N*P+O(1) =O(M*Ntest*P*d)$
6.小结
由实验结果及复杂度分析可知,基于PCA分类器的说话人识别不仅具有很好的识别率,而且时间复杂度较低, 是比较理想的说话人识别分类器。
参考文献
[1]《说话人识别模型与方法》吴朝辉 杨迎春 著 清华大学出版社 [2]基于PCA与LDA的说话人识别研究 章万峰 浙江大学硕士论文