1.概述
最近做了两个与语音识别相关的项目,两个项目的主要任务虽然都是语音识别,或者更确切的说是关键字识别,但开发的平台不同, 一个是windows下的,另一个是android平台的,于是也就选用了不同的语音识别平台,前者选的是微软的Speech API开发的,后者则选用 的是CMU的pocketsphinx,本文主要将一些常见的语音交互平台进行简单的介绍和对比。
这里所说的语音交互包含语音识别(Speech Recognition,SR,也称为自动语音识别,Automatic Speech Recognition,ASR)和语音 合成(Speech Synthesis,SS,也称为Text-To-Speech,简记为TTS)两种技术,另外还会提到声纹识别(Voice Print Recognition, 简记为VPR)技术。
语音识别技术是将计算机接收、识别和理解语音信号转变为相应的文本文件或者命令的技术。它是一门涉及到语音语言学、信号处理、 模式识别、概率论和信息论、发声机理和听觉机理、人工智能的交叉学科。在语音识别系统的帮助下,即使用户不懂电脑或者无法使用 电脑,都可以通过语音识别系统对电脑进行操作。
语音合成,又称文语转换(Text to Speech)技术,能将任意文字信息实时转化为标准流畅的语音朗读出来,相当于给机器装上了人工 嘴巴。它涉及声学、语言学、数字信号处理、计算机科学等多个学科技术,是中文信息处理领域的一项前沿技术,解决的主要问题就是如何 将文字信息转化为可听的声音信息,也即让机器像人一样开口说话。
下面按平台是否开源来介绍几种常见的语音交互平台,关于语音识别和语音合成技术的相关原理请参见我接下来的其他文章。
2.商业化的语音交互平台
1)微软Speech API
微软的Speech API(简称为SAPI)是微软推出的包含语音识别(SR)和语音合成(SS)引擎的应用编程接口(API),在Windows下应用 广泛。目前,微软已发布了多个SAPI版本(最新的是SAPI 5.4版),这些版本要么作为于Speech SDK开发包发布,要么直接被包含在windows 操作系统中发布。SAPI支持多种语言的识别和朗读,包括英文、中文、日文等。SAPI的版本分为两个家族,1-4为一个家族,这四个版本彼此 相似,只是稍微添加了一些新的功能;第二个家族是SAPI5,这个系列的版本是全新的,与前四个版本截然不同。
最早的SAPI 1.0于1995年发布,支持Windows 95和Windows NT 3.51。这个版本的SAPI包含比较初级的直接语音识别和直接语音合成的API, 应用程序可以直接控制识别或合成引擎,并简化更高层次的语音命令和语音通话的API。SAPI3.0于97年发布,它添加了听写语音识别(非连续 语音识别)和一些应用程序实例。98年微软发布了SAPI4.0,这个版本不仅包含了核心的COM API,用C++类封装,使得用C++来编程更容易, 而且还有ActiveX控件,这个控件可以再VB中拖放。这个版本的SS引擎随Windows2000一起发布,而SR引擎和SS引擎又一起以SDK的形式发布。
SAPI5.0 于2000年发布,新的版本将严格将应用与引擎分离的理念体现得更为充分,所有的调用都是通过动态调用sapi.dll来实现的, 这样做的目的是使得API更为引擎独立化,防止应用依赖于某个具有特定特征的引擎,这种改变也意图通过将一些配置和初始化的代码放 到运行时来使得应用程序的开发更为容易。
2).IBM viaVoice
IBM是较早开始语音识别方面的研究的机构之一,早在20世纪50年代末期,IBM就开始了语音识别的研究,计算机被设计用来检测特定的语言 模式并得出声音和它对应的文字之间的统计相关性。在1964年的世界博览会上,IBM向世人展示了数字语音识别的“shoe box recognizer”。 1984年,IBM发布的语音识别系统在5000个词汇量级上达到了95%的识别率。
1992年,IBM引入了它的第一个听写系统,称为“IBM Speech Server Series (ISSS)”。1996年发布了新版的听写系统,成为“VoiceType3.0”, 这是viaVoice的原型,这个版本的语音识别系统不需要训练,可以实现孤立单词的听写和连续命令的识别。VoiceType3.0支持Windows95系统, 并被集成到了OS/2 WARP系统之中。与此同时,IBM还发布了世界上首个连续听写系统“MedSpeak Radiology”。最后,IBM及时的在假日购物季节 发布了大众化的实用的“VoiceType Simply Speaking”系统,它是世界上首个消费版的听写产品(the world's first consumer dictation product).
1999年,IBM发布了VoiceType的一个免费版。2003年,IBM授权ScanSoft公司拥有基于ViaVoice的桌面产品的全球独家经销权,而ScanSoft公司 拥有颇具竞争力的产品“Dragon NaturallySpeaking”。两年后,ScanSoft与Nuance合并,并宣布公司正式更名为Nuance Communications,Inc。 现在很难找到IBM viaVoice SDK的下载地址了,它已淡出人们的视线,取而代之的是Nuance。
3)Nuance
Nuance通讯是一家跨国计算机软件技术公司,总部设在美国马萨诸塞州伯灵顿,主要提供语音和图像方面的解决方案和应用。目前的业务集中 在服务器和嵌入式语音识别,电话转向系统,自动电话目录服务,医疗转录软件与系统,光学字符识别软件,和台式机的成像软件等。
Nuance语音技术除了语音识别技术外,还包扩语音合成、声纹识别等技术。世界语音技术市场,有超过80%的语音识别是采用Nuance识别引擎技术, 其名下有超过1000个专利技术,公司研发的语音产品可以支持超过50种语言,在全球拥有超过20亿用户。据传,苹果的iPhone 4S的Siri语音识别中 应用了Nuance的语音识别服务。另外,据Nuance公司宣布的重磅消息,其汽车级龙驱动器Dragon Drive将在新奥迪A3上提供一个免提通讯接口, 可以实现信息的听说获取和传递。
Nuance Voice Platform(NVP)是Nuance公司推出的语音互联网平台。Nuance公司的NVP平台由三个功能块组成:Nuance Conversation Server 对话服务器,Nuance Application Environment (NAE)应用环境及Nuance Management Station管理站。Nuance Conversation Server对话服务 器包括了与Nuance语音识别模块集成在一起的VoiceXML解释器,文语转换器(TTS)以及声纹鉴别软件。NAE应用环境包括绘图式的开发工具, 使得语音应用的设计变得和应用框架的设计一样便利。Nuance Management Station管理站提供了非常强大的系统管理和分析能力,它们是为了 满足语音服务的独特需要而设计的。
4)科大讯飞——讯飞语音
提到科大讯飞,大家都不陌生,其全称是“安徽科大讯飞信息科技股份有限公司”,它的前身是安徽中科大讯飞信息科技有限公司,成立于99 年12月,07年变更为安徽科大讯飞信息科技股份有限公司,现在是一家专业从事智能语音及语音技术研究、软件及芯片产品开发、语音信息服务 的企业,在中国语音技术领域可谓独占鳌头,在世界范围内也具有相当的影响力。
科大讯飞作为中国最大的智能语音技术提供商,在智能语音技术领域有着长期的研究积累,并在中文语音合成、语音识别、口语评测等多项 技术上拥有国际领先的成果。03年,科大讯飞获迄今中国语音产业唯一的“国家科技进步奖(二等)”,05年获中国信息产业自主创新最高荣誉 “信息产业重大技术发明奖”。06年至11年,连续六届英文语音合成国际大赛(Blizzard Challenge)荣获第一名。08年获国际说话人识别评测 大赛(美国国家标准技术研究院—NIST 2008)桂冠,09年获得国际语种识别评测大赛(NIST 2009)高难度混淆方言测试指标冠军、通用测试 指标亚军。
科大讯飞提供语音识别、语音合成、声纹识别等全方位的语音交互平台。拥有自主知识产权的智能语音技术,科大讯飞已推出从大型电信级 应用到小型嵌入式应用,从电信、金融等行业到企业和家庭用户,从PC到手机到MP3/MP4/PMP和玩具,能够满足不同应用环境的多种产品,科大 讯飞占有中文语音技术市场60%以上市场份额,语音合成产品市场份额达到70%以上。
5)其他
其他的影响力较大商用语音交互平台有谷歌的语音搜索(Google Voice Search),百度和搜狗的语音输入法等等,这些平台相对于以上的4个 语音交互平台,应用范围相对较为局限,影响力也没有那么强,这里就不详细介绍了。
3.开源的语音交互平台
1)CMU-Sphinx
CMU-Sphinx也简称为Sphinx(狮身人面像),是卡内基 - 梅隆大学( Carnegie Mellon University,CMU)开发的一款开源的语音识别系统, 它包括一系列的语音识别器和声学模型训练工具。
Sphinx有多个版本,其中Sphinx1~3是C语言版本的,而Sphinx4是Java版的,另外还有针对嵌入式设备的精简优化版PocketSphinx。Sphinx-I 由李开复(Kai-Fu Lee)于1987年左右开发,使用了固定的HMM模型(含3个大小为256的codebook),它被号称为第一个高性能的连续语音识别 系统(在Resource Management数据库上准确率达到了90%+)。Sphinx-II由Xuedong Huang于1992年左右开发,使用了半连续的HMM模型, 其HMM模型是一个包含了5个状态的拓扑结构,并使用了N-gram的语言模型,使用了Fast lextree作为实时的解码器,在WSJ数据集上的识别率 也达到了90%+。
Sphinx-III主要由Eric Thayer 和Mosur Ravishankar于1996年左右开发,使用了完全连续的(也支持半连续的)HMM模型,具有灵活 的feature vector和灵活的HMM拓扑结构,包含可选的两种解码器:较慢的Flat search和较快的Lextree search。该版本在BN(98的测评数据 集)上的WER(word error ratio)为19%。Sphinx-III的最初版还有很多limitations,诸如只支持三音素文本、只支持Ngram模型(不 支持CFG/FSA/SCFG)、对所有的sound unit其HMM拓扑结构都是相同的、声学模型也是uniform的。Sphinx-III的最新版是09年初发布的0.8版, 在这些方面有很多的改进。
最新的Sphinx语音识别系统包含如下软件包: Pocketsphinx — recognizer library written in C. Sphinxbase — support library required by Pocketsphinx Sphinx4 — adjustable, modifiable recognizer written in Java CMUclmtk — language model tools Sphinxtrain — acoustic model training tools 这些软件包的可执行文件和源代码在sourceforge上都可以免费下载得到。
2)HTK
HTK是Hidden Markov Model Toolkit(隐马尔科夫模型工具包)的简称,HTK主要用于语音识别研究,现在已经被用于很多其他方面的研究, 包括语音合成、字符识别和DNA测序等。
HTK最初是由剑桥大学工程学院(Cambridge University Engineering Department ,CUED)的机器智能实验室(前语音视觉及机器人组) 于1989年开发的,它被用来构建CUED的大词汇量的语音识别系统。93年Entropic Research Laboratory Inc.获得了出售HTK的权利,并在95年 全部转让给了刚成立的Entropic Cambridge Research Laboratory Ltd,Entropic一直销售着HTK,直到99年微软收购了Entropic,微软重新 将HTK的版权授予CUED,并给CUED提供支持,这样CUED重新发布了HTK,并在网络上提供开发支持。
HTK的最新版本是09年发布的3.4.1版,关于HTK的实现原理和各个工具的使用方法可以参看HTK的文档HTKBook。
3)Julius
Julius是一个高性能、双通道的大词汇量连续语音识别(large vocabulary continues speech recognition,LVCSR)的开源项目, 适合于广大的研究人员和开发人员。它使用3-gram及上下文相关的HMM,在当前的PC机上能够实现实时的语音识别,单词量达到60k个。
Julius整合了主要的搜索算法,高度的模块化使得它的结构模型更加独立,它同时支持多种HMM模型(如shared-state triphones 和 tied-mixture models等),支持多种麦克风通道,支持多种模型和结构的组合。它采用标准的格式,这使得和其他工具箱交叉使用变得 更容易。它主要支持的平台包括Linux和其他类Unix系统,也适用于Windows。它是开源的,并使用BSD许可协议。
自97年后,Julius作为日本LVCSR研究的一个自由软件工具包的一部分而延续下来,后在2000年转由日本连续语音识别联盟(CSRC)经营。 从3.4版起,引入了被称为“Julian”的基于语法的识别解析器,Julian是一个改自Julius的以手工设计的DFA作为语言模型的版本,它可以 用来构建小词汇量的命令识别系统或语音对话系统。
4)RWTH ASR
该工具箱包含最新的自动语音识别技术的算法实现,它由 RWTH Aachen 大学的Human Language Technology and Pattern Recognition Group 开发。
RWTH ASR工具箱包括声学模型的构建、解析器等重要部分,还包括说话人自适应组件、说话人自适应训练组件、非监督训练组件、个性化 训练和单词词根处理组件等,它支持Linux和Mac OS等操作系统,其项目网站上有比较全面的文档和实例,还提供了现成的用于研究目的的 模型等。
该工具箱遵从一种从QPL发展而来的开源协议,只允许用于非商业用途。
5)其他
上面提到的开源工具箱主要都是用于语音识别的,其他的开源语音识别项目还有Kaldi 、simon 、iATROS-speech 、SHoUT 、 Zanzibar OpenIVR 等。
常见的语音合成的开源工具箱有MARY、SpeakRight、Festival 、FreeTTS 、Festvox 、eSpeak 、Flite 等。
常见的声纹识别的开源工具箱有Alize、openVP等。
4.小结
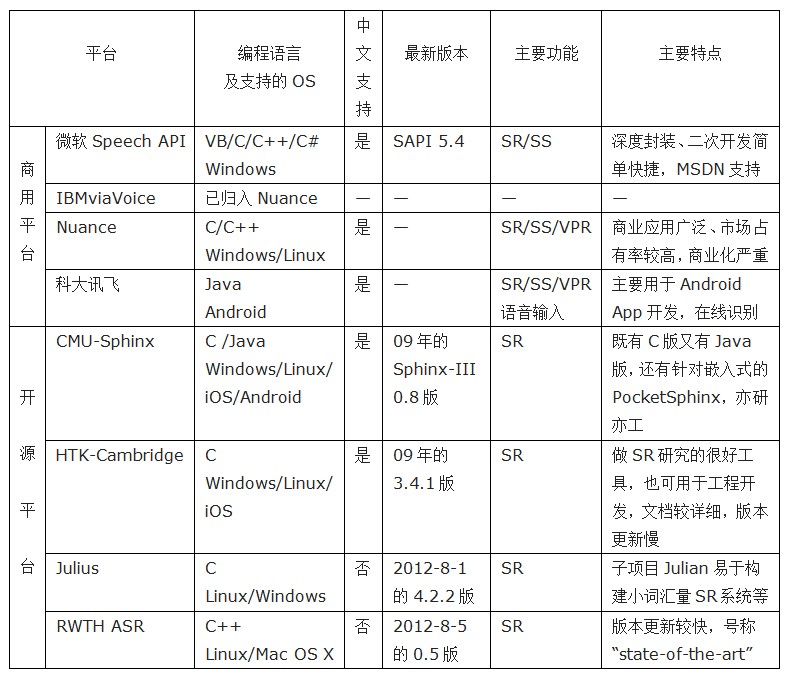
本文介绍了几种常见的语音交互平台,主要是语音识别、语音合成的软件或工具包,还顺便提到了声纹识别的内容, 下面做一个简单的总结:
参考文献
[1]语音识别-维基百科:http://zh.wikipedia.org/wiki/语音识别 [2]语音合成-百度百科:http://baike.baidu.com/view/549184.htm [3] Microsoft Speech API:http://en.wikipedia.org/wiki/Speech_Application_Programming_Interface#SAPI_1 [4] MSDN-SAPI:http://msdn.microsoft.com/zh-cn/library/ms723627.aspx [5] 微软语音技术 Windows 语音编程初步:http://blog.csdn.net/yincheng01/article/details/3511525 [6]IBM Human Language Technologies History:http://www.research.ibm.com/hlt/html/history.html [7] Nuance: http://en.wikipedia.org/wiki/Nuance_Communications [8] 科大讯飞:http://baike.baidu.com/view/362434.htm [9] CMU-Sphinx: http://en.wikipedia.org/wiki/CMU_Sphinx [10] CMU Sphinx homepage:http://cmusphinx.sourceforge.net/wiki/ [11] HTK Toolkit:http://htk.eng.cam.ac.uk/ [12] Julius:http://en.wikipedia.org/wiki/Julius_(software) [13] RWTH ASR:http://en.wikipedia.org/wiki/RWTH_ASR [14] List of speech recognition software: http://en.wikipedia.org/wiki/List_of_speech_recognition_software [15] Speech recognition: http://en.wikipedia.org/wiki/Speech_recognition [16] Speech synthesis: http://en.wikipedia.org/wiki/Speech_synthesis [17] Speaker recognition: http://en.wikipedia.org/wiki/Speaker_recognition