1.概述(Introduction)
本系列文主要介绍语音信号时域的4个基本特征及其Python实现,这4个基本特征是: (1)音量(Volume); (2)过零率(Zero-Crossing-Rate); (3)音高(Pitch); (4)音色(Timbre)。
2.音量(Volume)
音量代表声音的强度,可由一个窗口或一帧内信号振幅的大小来衡量,一般有两种度量方法: (1)每个帧的振幅的绝对值的总和:
音量计算的Python实现如下:
import math
import numpy as np
# method 1: absSum
def calVolume(waveData, frameSize, overLap):
wlen = len(waveData)
step = frameSize - overLap
frameNum = int(math.ceil(wlen*1.0/step))
volume = np.zeros((frameNum,1))
for i in range(frameNum):
curFrame = waveData[np.arange(i*step,min(i*step+frameSize,wlen))]
curFrame = curFrame - np.median(curFrame) # zero-justified
volume[i] = np.sum(np.abs(curFrame))
return volume
# method 2: 10 times log10 of square sum
def calVolumeDB(waveData, frameSize, overLap):
wlen = len(waveData)
step = frameSize - overLap
frameNum = int(math.ceil(wlen*1.0/step))
volume = np.zeros((frameNum,1))
for i in range(frameNum):
curFrame = waveData[np.arange(i*step,min(i*step+frameSize,wlen))]
curFrame = curFrame - np.mean(curFrame) # zero-justified
volume[i] = 10*np.log10(np.sum(curFrame*curFrame))
return volume
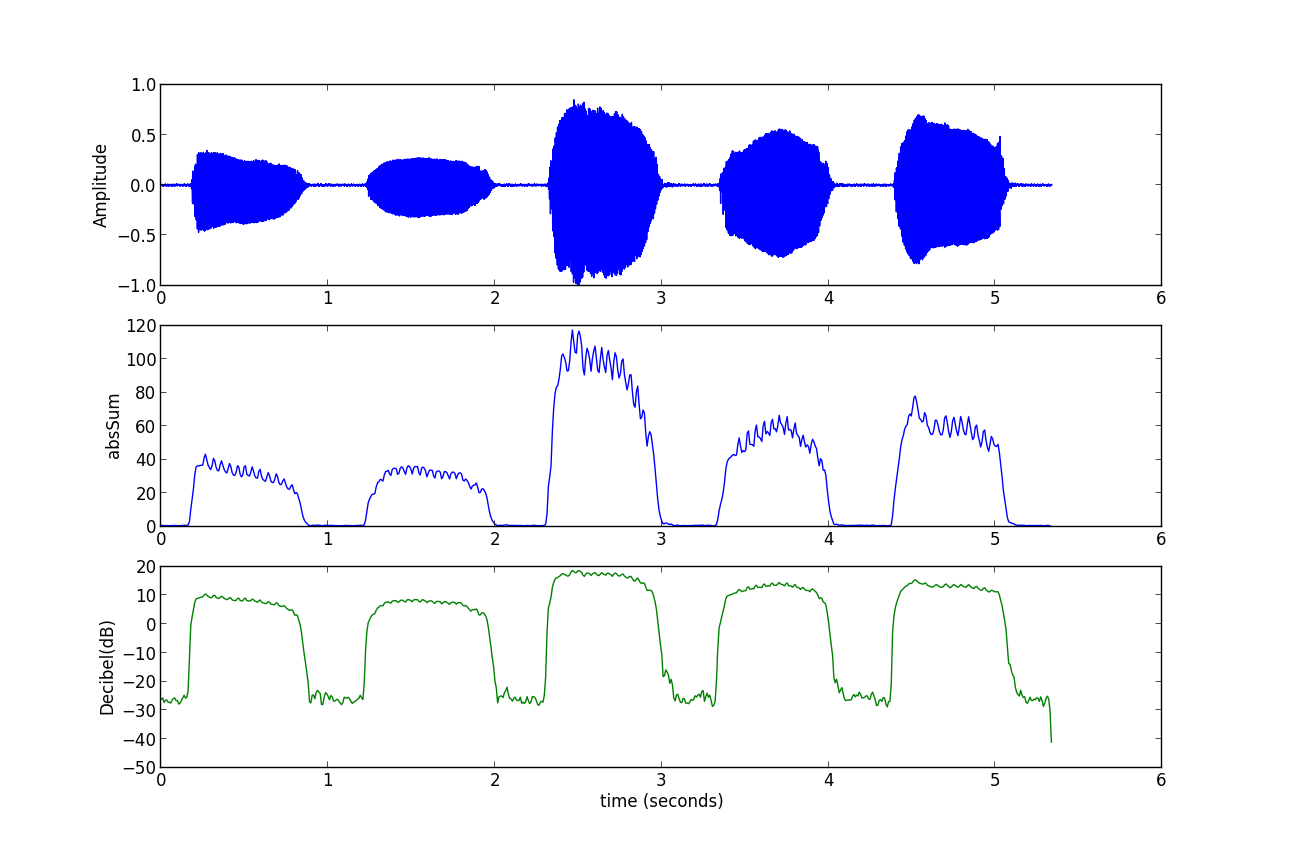
对于给定语音文件aeiou.wav,利用上面的函数计算音量曲线的代码如下:
import wave
import pylab as pl
import numpy as np
import Volume as vp
# ============ test the algorithm =============
# read wave file and get parameters.
fw = wave.open('aeiou.wav','r')
params = fw.getparams()
print(params)
nchannels, sampwidth, framerate, nframes = params[:4]
strData = fw.readframes(nframes)
waveData = np.fromstring(strData, dtype=np.int16)
waveData = waveData*1.0/max(abs(waveData)) # normalization
fw.close()
# calculate volume
frameSize = 256
overLap = 128
volume11 = vp.calVolume(waveData,frameSize,overLap)
volume12 = vp.calVolumeDB(waveData,frameSize,overLap)
# plot the wave
time = np.arange(0, nframes)*(1.0/framerate)
time2 = np.arange(0, len(volume11))*(frameSize-overLap)*1.0/framerate
pl.subplot(311)
pl.plot(time, waveData)
pl.ylabel("Amplitude")
pl.subplot(312)
pl.plot(time2, volume11)
pl.ylabel("absSum")
pl.subplot(313)
pl.plot(time2, volume12, c="g")
pl.ylabel("Decibel(dB)")
pl.xlabel("time (seconds)")
pl.show()
运行以上程序得到下图:
参考(References)
[1]Volume (音量):http://neural.cs.nthu.edu.tw/jang/books/audiosignalprocessing/basicFeatureVolume.asp?title=5-2%20Volume%20(%AD%B5%B6q) [2]用Python做科学计算-声音的输入输出:http://hyry.dip.jp:8000/pydoc/wave_pyaudio.html