
一、教程&博客
1. Flink中文视频教程
Flink系列视频教程:https://github.com/flink-china/flink-training-course
基础篇 https://ververica.cn/developers/flink-training-course-basics/
进阶篇 https://ververica.cn/developers/flink-training-course-advanced/
运维篇 https://ververica.cn/developers/flink-training-course-operation/
实时数仓篇 https://ververica.cn/developers/flink-training-course-data-warehouse/
技术生态篇 https://ververica.cn/developers/flink-training-course-technological-ecology/
社区成长篇 https://ververica.cn/developers/flink-training-course-growup/
1.10版特别篇 https://ververica.cn/developers/flink-training-course-1-10/
2.博客
1)CN: 伍 翀(WuChong) | EN: Jark | 花名: 云邪 的博客
http://wuchong.me/archives/
https://wuchong.me/categories/Flink/
2)王无知
https://www.cnblogs.com/importbigdata/p/11431859.html
https://www.cnblogs.com/importbigdata/tag/Flink/
二、Flink简介
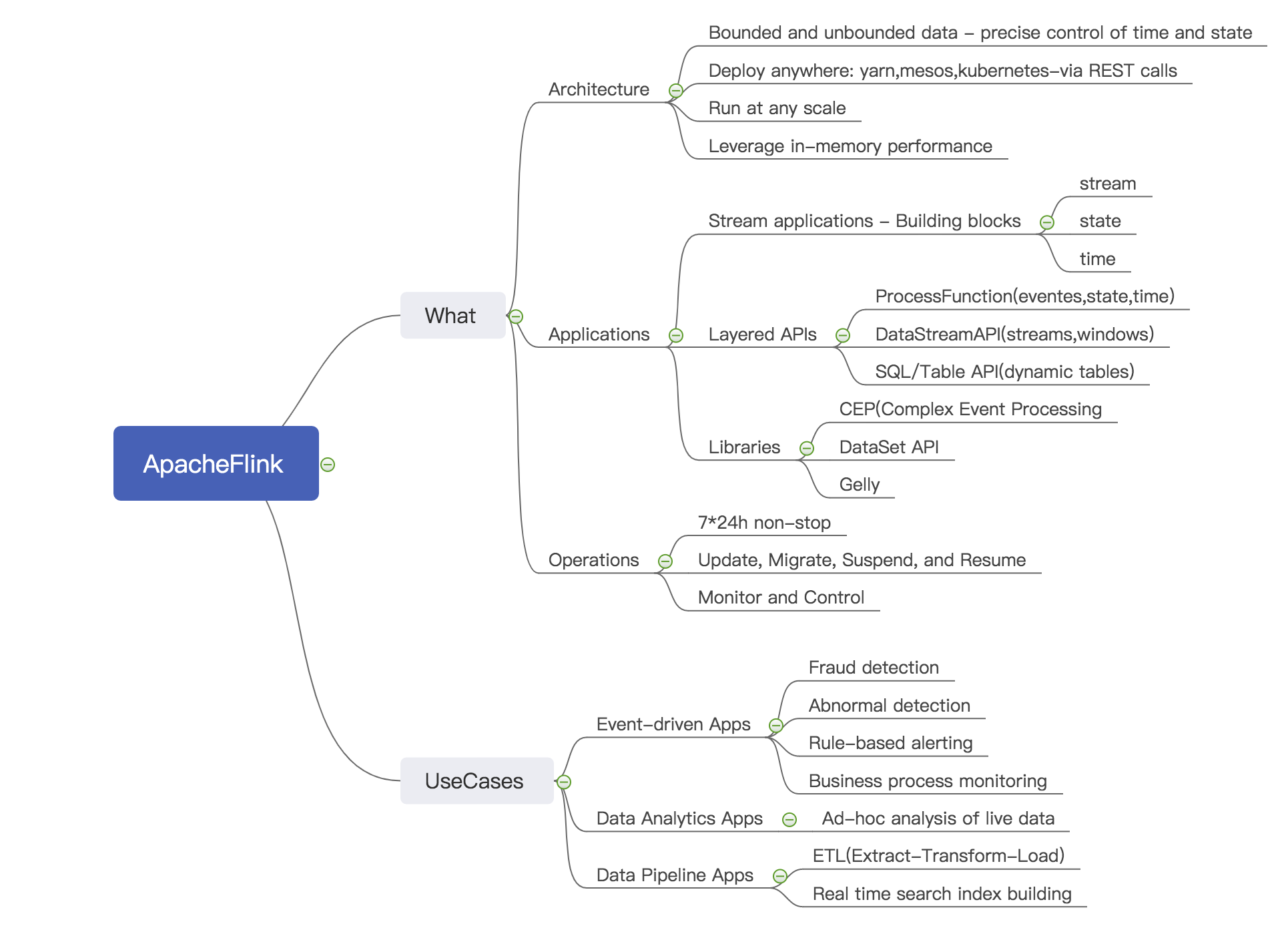
1、Features:
support for stream and batch processing
sophisticated state management
event-time processing semantics
exactly-once consistency guarantees for state
can be deployed on various resource providers
2、Architecture
1) Process bounded and unbounded data
precise control of time and state
2)Deploy applications anywhere
Flink integrates with all common cluster resource managers such as Hadoop YARN, Apache Mesos, and Kubernetes but can also be setup to run as a stand-alone cluster.
All communication to submit or control an application happens via REST calls.
3) Run applications at any scale
4)Leverage in-memory performance
Task state is always maintained in memory or, if the state size exceeds the available memory, in access-efficient on-disk data structures.
3、Applications
1)Building blocks for stream applications
stream,state,time
2)Layered APIs
three layered APIs:
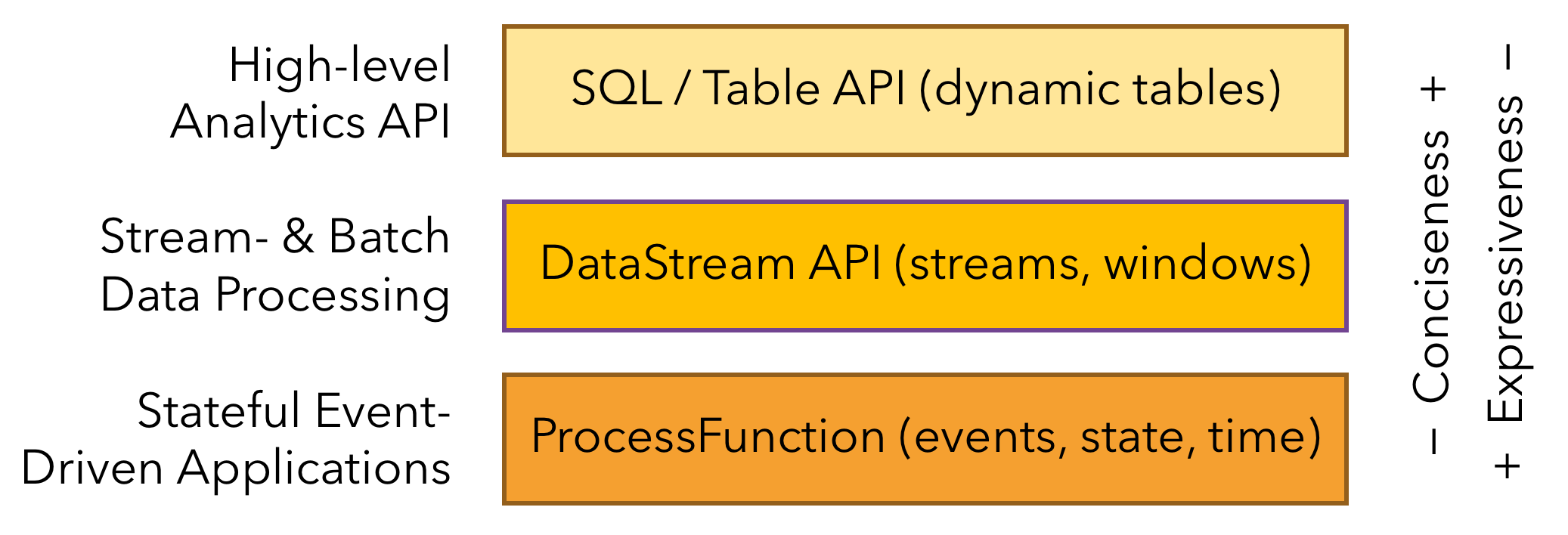
3)Libraries
CEP/DataSet API/Gelly
4、Operations
1)7*24h non-stop
2)Update, Migrate, Suspend, and Resume
3)Monitor and Control
5、Use Cases
Event-driven Apps
Data Analytics Apps
Data Pipeline Apps