原文链接:https://zhuanlan.zhihu.com/p/701181424
大家好,我是凉夏同学。今天是我第一次在知乎分享我对算法模型的理解,有些生疏,还请大家多多指教。感兴趣的话,敬请关注公众号:凉夏的机器学习笔记。感恩~
今天要讲的是最近比较火的一种网络结构,可以近乎“无脑地”加入到网络结构当中,基本上都可以带来或多或少的效果提升。这个网络结构有人叫他门控网络、门控结构,也有人叫他的英文名“gating”,也有人叫他动态权重。
这篇文章,我会先讲一下我对门控机制的理解,然后会简单介绍几个使用门控机制的论文。
门控的本质
一直都觉得深度学习模型架构里,很多东西都是相同的,虽然很多时候他们有不同的名称、亦或是用在了不同的模型位置,但底层的思想和逻辑很可能是一致的。而我认为,门控网络结构的本质就是注意力机制。说到注意力机制,大家应该都不陌生,该结构出现在以DNN模型为基础的各种应用结构中,例如:transformer里面使用了multi-head attention(MHA)这种多头自注意力机制;用户行为序列建模DIN结构使用了target attention结构。
那么注意力机制的本质又是什么呢?我的理解是:注意力机制就是自适应学习得到权重。所以相关结构可以再进行细分,得到三种关键元素:
- ①输入:使用哪些信息作为注意力的输入;
- ②结构:如何计算注意力权重;
- ③输出:得到了权重之后,我们要作用在哪里。
基本上,我们见到的任何注意力机制都可以归因到上面三个问题上。
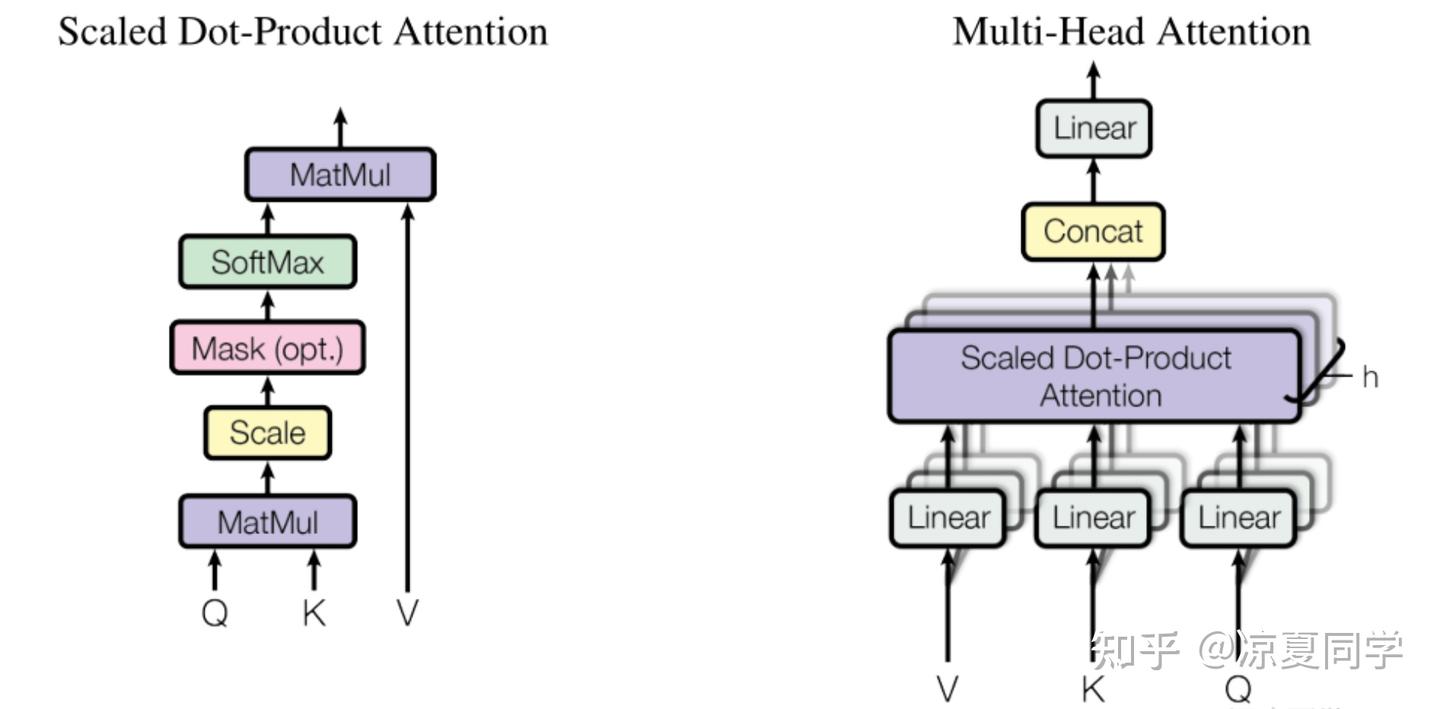
拿我们举例子的transformer中的多头注意力机制来说。如果是encoder那侧,那么则是自注意力机制,输入是同一个序列的token经过矩阵转换之后的向量;注意力计算方式是Scaled(除以根号d)的内积再softmax;输出依旧作用在当前序列上。如果是DIN结构,那输入是target poi的embedding,计算方式则是简单的内积,输出在用户序列的每个seq poi的embedding上。
简单介绍完了注意力机制,说回来我们的门控。既然门控本质也是注意力机制,那么其三元素也是包括输入、结构、输出。只是相应的内容有一些变化,从而衍生出不同的网络结构和应用。下面介绍一些常见的。
LHUC结构
LHUC的全称是Learning Hidden Unit Contributions,最早语音识别领域所提出的,其核心的思想是:为每一个 speaker 定制一个振幅函数 (amplitude function),作用于 DNN 的隐层之上。从公式上看非常直观:
其中 代表哈达玛积,也就是两个向量对应位置的元素相乘。其右边代表DNN某个隐藏层输出(因为大概形式就是f(w·x+b)嘛),其左边代表振幅函数的输出。虽说名字叫做振幅函数,但整个公式的形式看起来非常符合我们上文讨论的注意力机制的形式——生成了权重乘在隐藏层的输出上。其输入就是每个speaker的信息,结构就是浅层的DNN,输出作用在DNN的多个隐藏层上。其中有一个细节是,一般来说作为权重的DNN子结构会使用sigmoid作为激活函数,使得权重在0~1之间。而LHUC在sigmoid前面乘了个固定数字“2”,使得权重在0~2之间。带来的效果是:若权重在0~1之间,则是对原有隐藏层数值的抑制;若权重在1~2之间,则是对原有数值的放大。
PPNet
PPNet的全称是Parameter Personalized Net,是快手提出的模型架构,将上述语音领域的LHUC架构搬到了推荐领域,将每一个“speaker”当做是每一个用户,从而提升模型个性化效果。
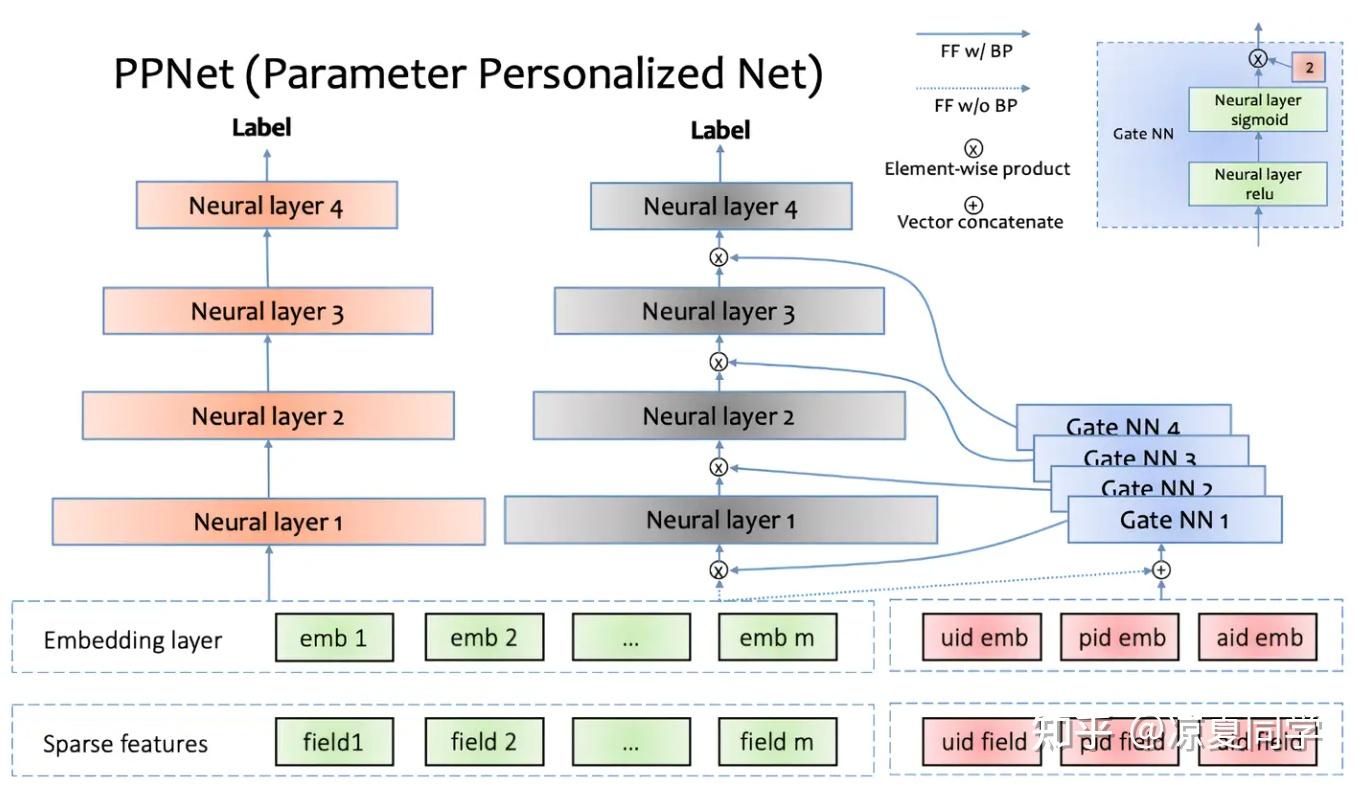
我们看下PPNet的门控结构的输入输出和网络结构。其输入的特征uid,pid,aid 分别表示 user id,photo id,author id,将这三个id输入门控网络得到全部其他隐藏层元素维度的权重,具体要作用在哪一层的时候,就直接将门控网络的输出维度设置成相同的即可。而在图的右上角我们可以看到门控网络的具体结构,是两层的MLP网络——第一层NN是以ReLU作为激活函数,第二层是sigmoid作为激活函数同时在输出之后和LHUC一样乘了“2”。PPNet 中的门控结构比较轻量化,而且很容易移植到工业界各个大厂的排序模型当中,因此在最近几年是一个比较火的网络子结构。
这里我们简单提一下两层MLP的好处。因为要输出全部隐藏层(尤其是第一层是全部特征embedding拼接之后的维度)元素维度的权重,因此参数量一般会比较大。而两层的MLP可以通过降低第一层NN的输出维度,使得门控结构“先降维、后升维”从而降低参数量。类似的思想在SENet,或者大模型SFT的lora结构都有所体现。
以上是门控机制在推荐模型中的一个应用实例。如前文所说,深度学习模型架构里很多东西都是相同的,后续会介绍更多使用了门控机制的网络架构,但本质上都和PPNet或者LHUC非常类似,其核心思想都是注意力机制,区别基本在于输入、输出和网络架构。
PEPNet
PEPNet全称是Parameter and Embedding Personalized Network,可以看到只在PPNet的基础上多了一个Embedding Personalized Network。体现在结构细节上,就是除了原先使用三个id特征做模型结构中间隐藏层的个性化之外,新增了使用场景特征对全部特征提前做一次个性化。
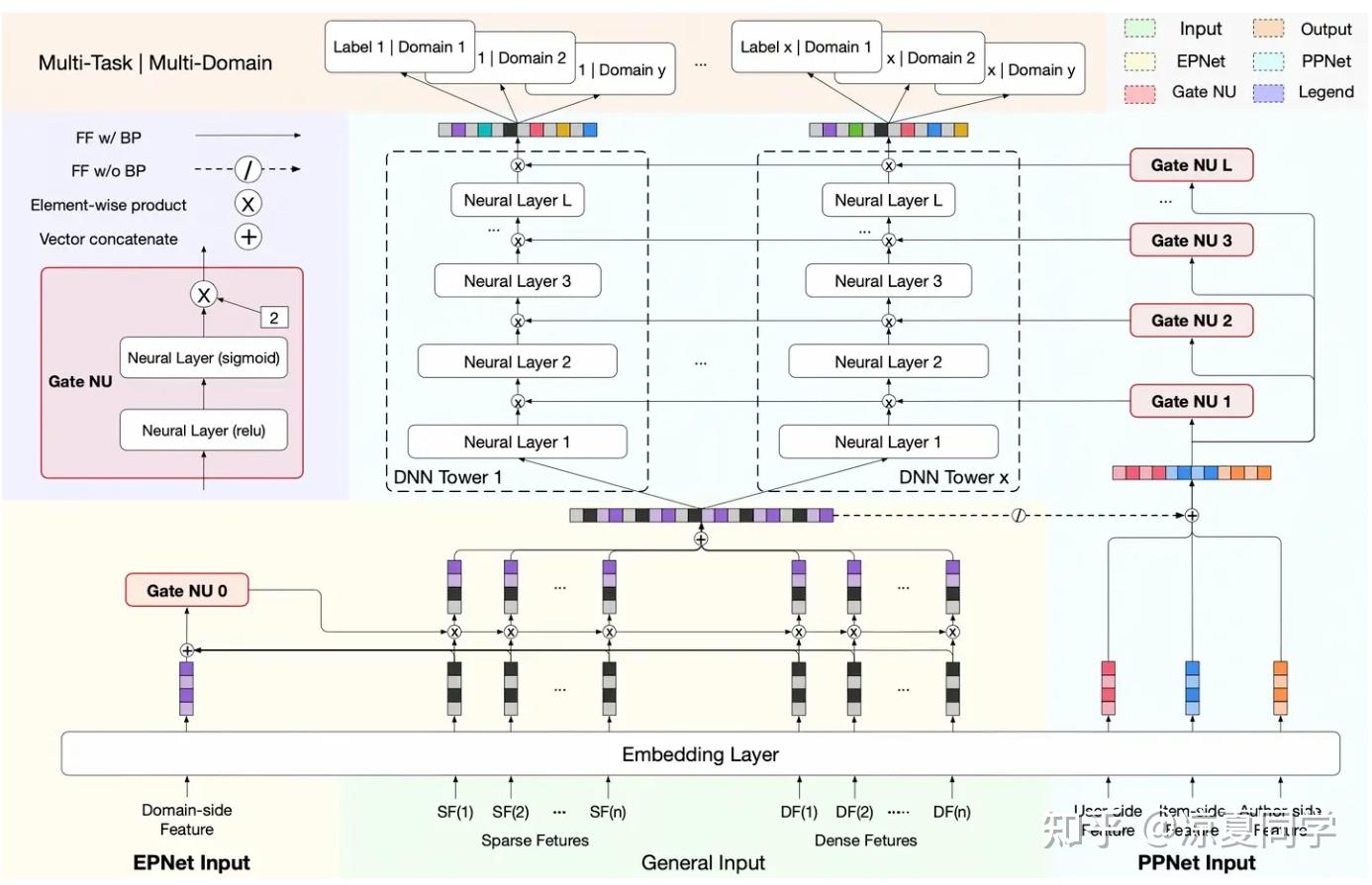
如图所示,右侧依旧是PPNet,只是左下角新增了使用场景特征计算全部特征的个性化。有一个小细节就是场景特征同时作为门控的输入和主网络的输入,也就是二者共享embedding的。在其作为门控输入的时候进行stop gradient,防止其梯度影响主网络。
AdaSpase
AdaSparse,阿里2022年的论文《Learning Adaptively Sparse Structures for Multi-Domain Click-Through Rate Prediction》。文章也是使用到了门控机制,只是输入输出有一些差异,以及其中结合“稀疏”的思想体现了一些创新的出发点。模型如图所示,右侧②是门控网络的结构,可以看到输入使用了整个隐藏层的向量拼接上场景特征向量一起作为输入;网络结构结合了不同稀疏效果的设计了Binarization、Scaling、Fusion三种方法;最终也是作为权重与当前隐藏层进行元素乘,只是由于不同方法的稀疏性不同,所产生的效果不同。
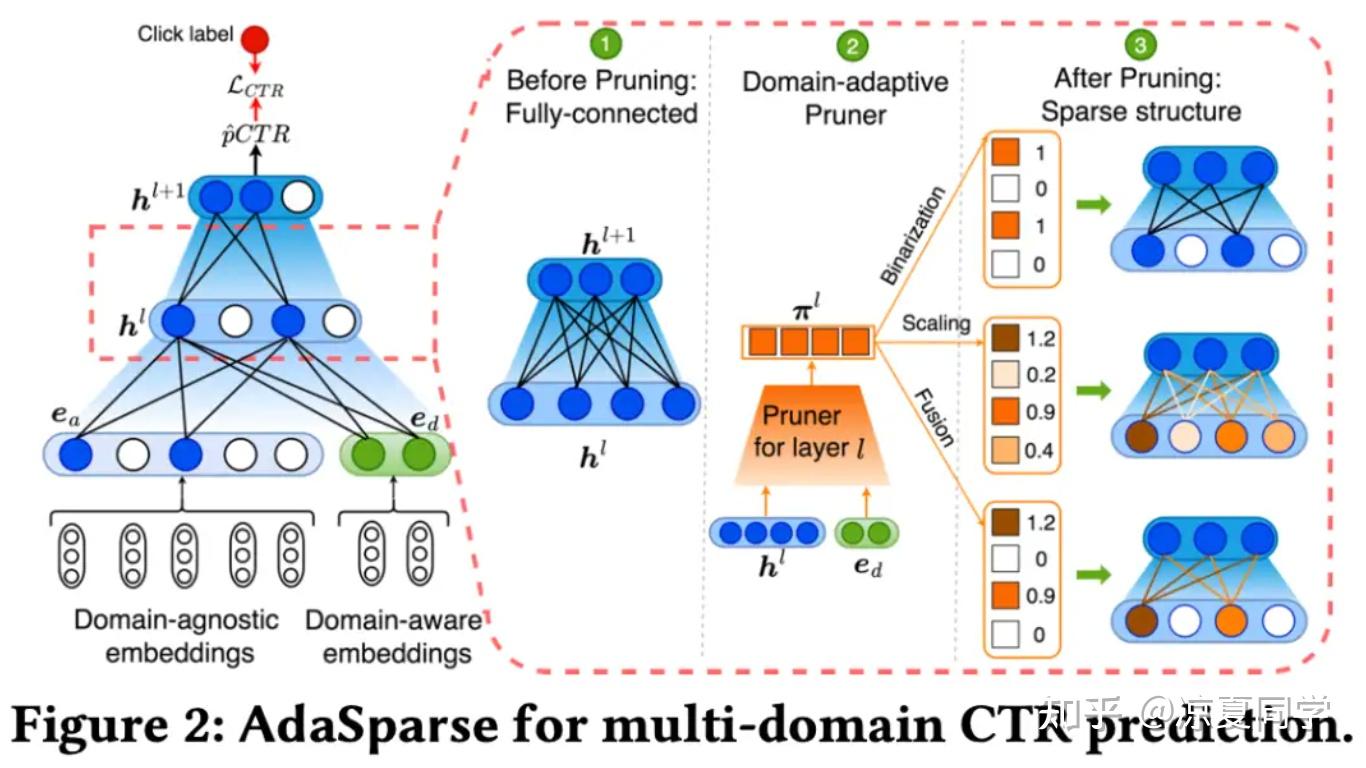
AdaSparse将门控网络称之为”场景自适应的裁剪器“,其主要结构也是DNN,公式如下图:
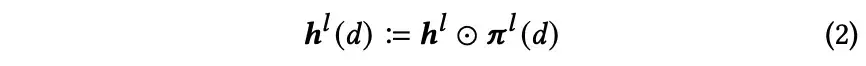
第l层的隐藏层和相应的权重进行元素乘
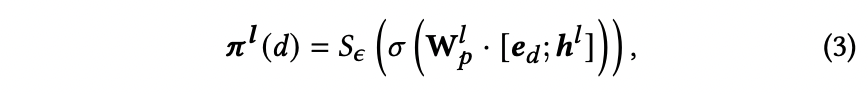
权重的输入是向量拼接后经过一层MLP和sigmoid,之后再输入到另一个函数S
其中S则代表了Binarization、Scaling、Fusion三种方法。Binarization是将输入的绝对值和阈值ε输入符号函数sign中,如果输入的绝对值大于ε,那么经符号函数输出1,反之输出0。
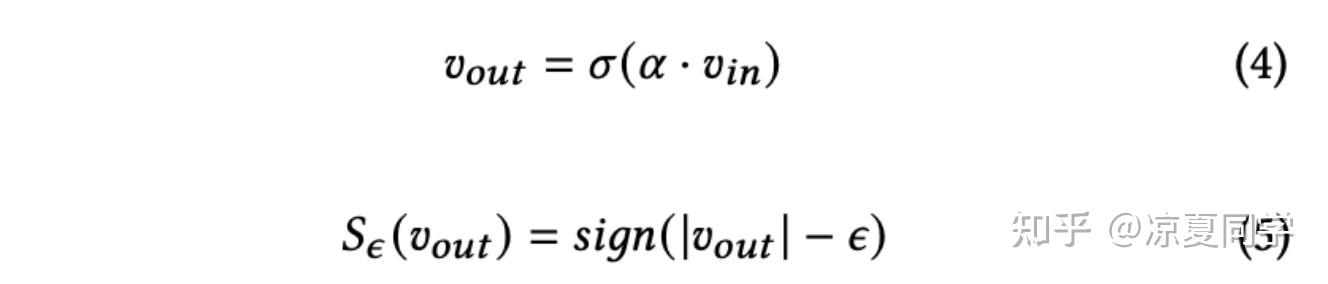
Scaling方法则是:sigmoid之后乘上缩放因子β(类似于LHUC里面的”2“),再将符号函数的输出再乘上原来的值。大概思路是:经过符号函数变为1或者0,会损失信息,如果再乘上原来的值,不仅可以知道隐藏层对应位置的信息是否要保留(对应裁剪器同位置权重是否为1),还能知道权重的大小幅度。
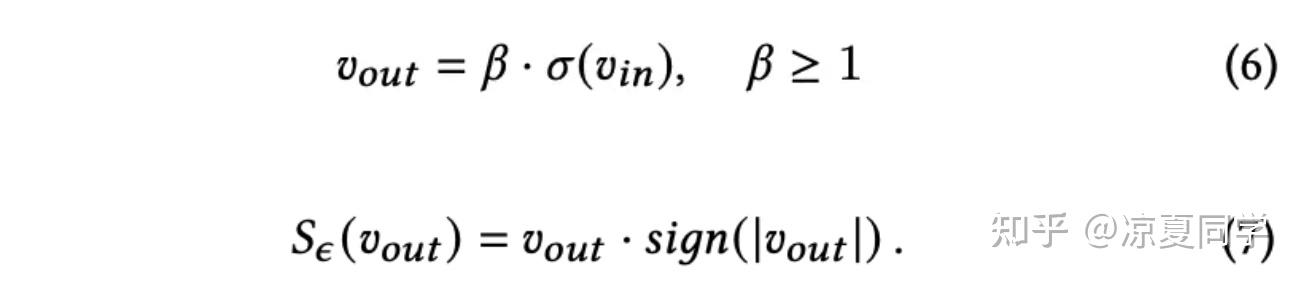
Fusion方法则是将上述两种思路结合起来,我们从公式上可以看出来。
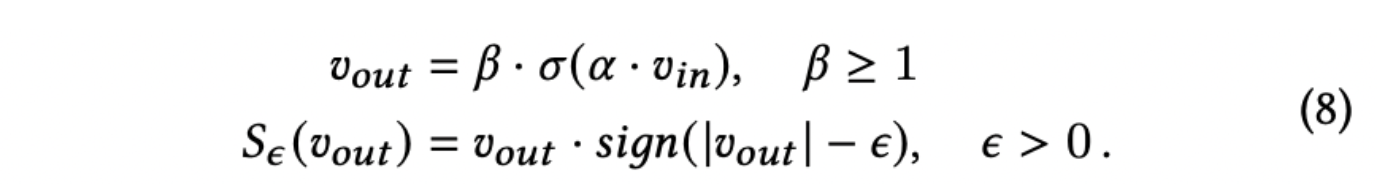
以上是AdaSparse门控网络的几种形式,具体哪种效果好,我们可以通过实验来确定。那么其中的稀疏是如何得到的呢?论文中将是通过将L1正则项加入到loss中得到的,而这个loss会随着训练而慢慢增大,带来的效果就是训练初期参数比较稠密,最大程度保留信息;随着训练的进行,loss逐渐变大,从而得到稀疏权重。而稀疏的优点,论文中大概是说,可以提升泛化性——因为我们是将场景特征作为门控的输入的,也就是场景特征来控制哪些特征要保留——从而可以减少不同场景的互相影响,而提升泛化性吧。我个人是这么理解的。
M2M
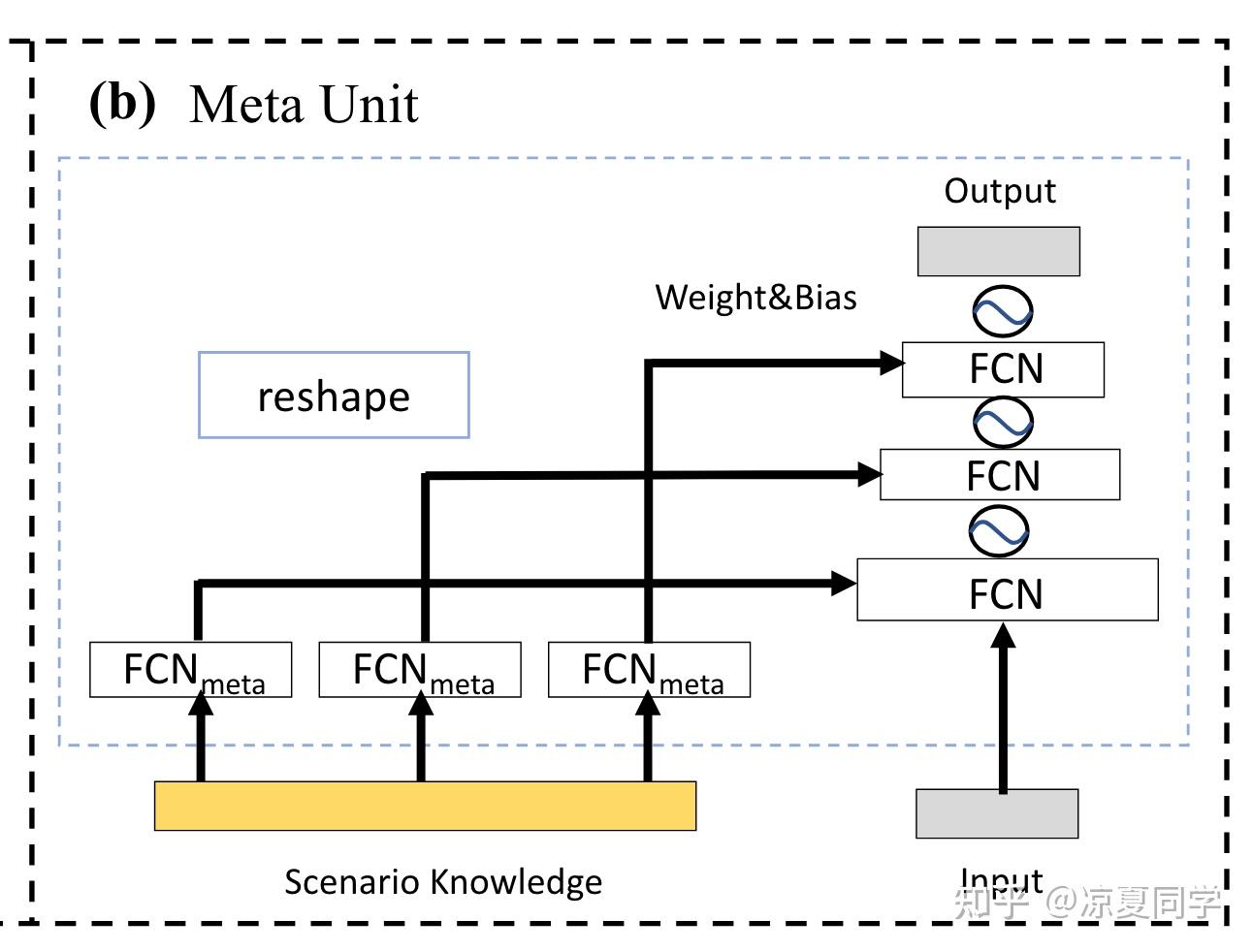
出自阿里的论文《Leaving No One Behind: A Multi-Scenario Multi-Task Meta Learning Approach for Advertiser Modeling》,两个”M“,分别对应了多场景和多目标,其中多场景是使用门控机制来解决的,多目标使用的是传统的MMOE。而这里的门控网络并不是在输出权重作用在隐藏层上,而是通过Meta Unit模块,根据“场景”特征,动态生成权重,再reshape成一个MLP。