原文链接:https://zhuanlan.zhihu.com/p/635429751
So-vits-svc(SoftVC VITS Singing Voice Conversion)是一款开源免费AI语音转换软件,最近大火的AI孙燕姿利用的也是这一技术:
github.com/svc-develop-team/so-vits-svc
so-vits-svc可以通过学习一个人的声音,对另一首歌做音色替换。所需的样本量较少,且少量的训练时间就可以得到不错的效果。
但如果要真的跑so-vits-svc,步骤非常多,目前的门槛还是很高的。B站上有大神做了整合包,这个门槛会稍微低一点:
但目前网络上关于so-vits-svc的教程,大多没有把从下载、数据准备、模型训练到最终歌曲生成的整个流程讲清楚。
这篇文章会讲述在Windows系统中,利用so-vits-svc进行声音克隆的完整过程。
在进入教程之前你需要满足几个条件:
- 有N卡,且内存在6G以上,并安装了对应的CUDA环境
- 可以登录外网
一、下载so-vits-svc
1. 创建新的conda环境
首先你需要在电脑上安装Anaconda,生成一个新的环境,方便不同Python包的版本管理:
conda create --name so-vits-svc
激活该环境:
conda activate so-vits-svc
2. Git clone项目
首先把该项目下载到本地
git clone https://github.com/svc-develop-team/so-vits-svc.git
进入项目文件夹
cd .\so-vits-svc\
3. 安装所需的Python环境
pip install -r requirements_win.txt
注意:安装过程中,可能会有个别包安装失败。安装失败后,可以手动安装,例如我遇到了faiss, edge-tts, fairseq这三个包安装识别,然后自己手动通过pip安装:
pip install faiss-cpu
pip install edge-tts
pip install fairseq
4. 下载预训练模型文件
下载地址:checkpoint_best_legacy_500.pt | Powered by Box
下载得到checkpoint_best_legacy_500.pt文件,放到.\so-vits-svc\pretrain文件夹中。
二、准备训练集
so-vits-svc需要唱歌或者说话的音频文件作为训练集,这里以唱歌的音频为例。
准备训练集时,需要把人声提取出来,去掉和声和伴奏。然后把人声切成30秒以内的片段。
1. 歌曲下载
首先你需要下载一个人唱歌的音频,尽量下载无损音质(flac., wav.),音频的数量建议在20首以上。
2. 提取人声
人声的提取需要用到Ultimate Vocal Remover,这是一个基于深度学习的人声、伴奏分离工具:
github.com/Anjok07/ultimatevocalremovergui
GitHub上有下载地址:
https://github.com/Anjok07/ultimatevocalremovergui/releases/download/v5.5.0/UVR_v5.5.1_setup.exe
下载好Ultimate Vocal Remover,需要分别去除伴奏、和声,才能得到干净的人声:
(1)去除伴奏
去除伴奏利用MDX-Net:
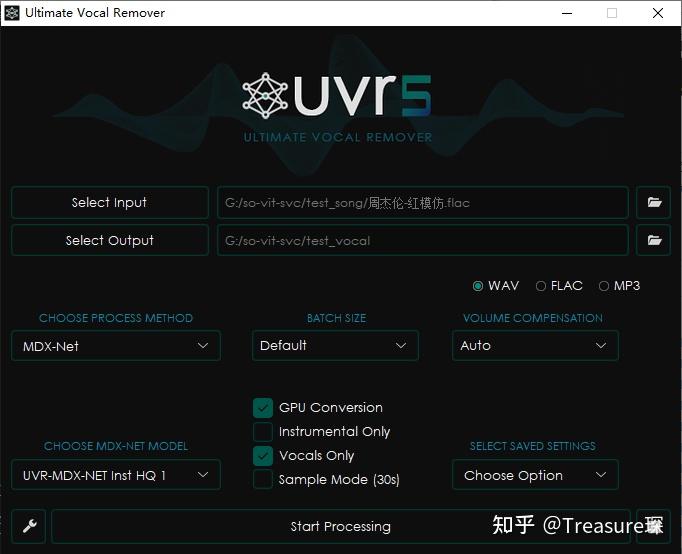
(2)去除和声
把去除伴奏了的歌曲文件,利用VR Architecture去除和声:
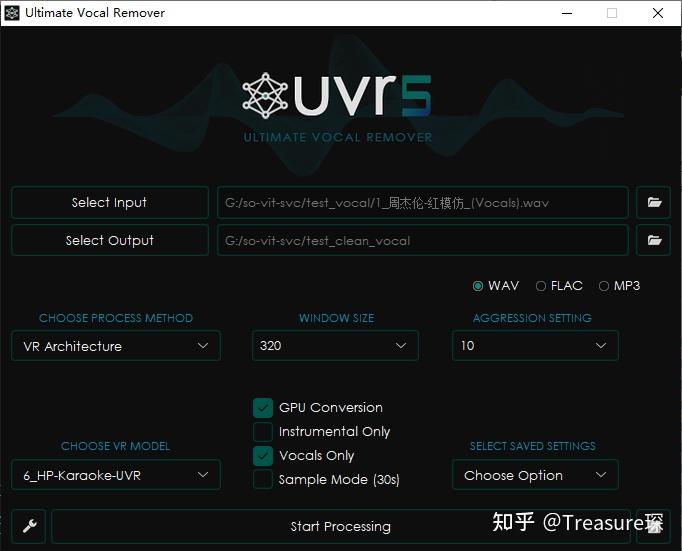
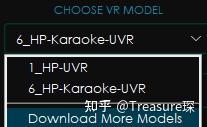
如果左下角Choose VR Model中只有1_HP-UVR,可以通过Download More Models下载6_HP-Karaoke-UVR这个模型。
最后就可以得到干净的人声了。
3. 音频切片
得到了干净的人声后,需要把音频切成30s以内的片段,且去除没有人声的片段,只保留有人声的片段。
音频切片需要用到开源的Audio Slicer工具:
github.com/flutydeer/audio-slicer
下载地址:Releases · flutydeer/audio-slicer
添加人声文件,设置好输出文件夹,采用默认设置就可以了:
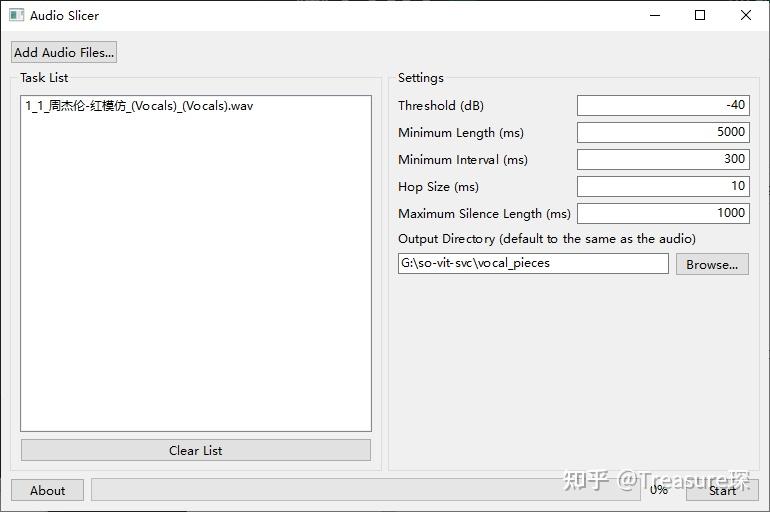
最终得到的音频片段:
数据集准备好后,在.\so-vits-svc\dataset_raw文件夹中新建一个文件夹,命名为该音色的名字,例如:
.\so-vits-svc\dataset_raw\jayzhou
把所有声音片段放在都放在这个文件夹下。
三、模型训练
1. 导入训练集
确保激活了conda环境,且当前目录为.\so-vits-svc\,在command window中依次输入
python resample.py
python preprocess_flist_config.py
python preprocess_hubert_f0.py
2. 开始训练
导入训练集后,可以开始训练
python train.py -c configs/config.json -m 44k
如果成功开始训练,可以得到每个Epoch的时间、loss以及模型保存的信息:
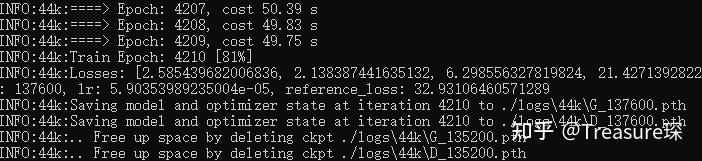
建议至少训练1000个Epoch。
可以通过Ctrl+C停止训练。
四、音色替换
1. 准备干净的人声以及伴奏
so-vits-svc本质是对干净的人声进行音色替换,所以需要做替换的音频,也应该是干净的人声。
下载一首新的歌曲,重复提取人声那一部分,去除和声和伴奏。
去除伴奏的时候,不用勾选Vocal Only,这样就能得到歌曲的伴奏。在后面人声、伴奏混合时可以用到。
2. 打开WebUI
python .\webUI.py
Running on local URL: http://127.0.0.1:7860
在浏览器中输入http://127.0.0.1:7860,可以打开WebUI:
(1)加载模型
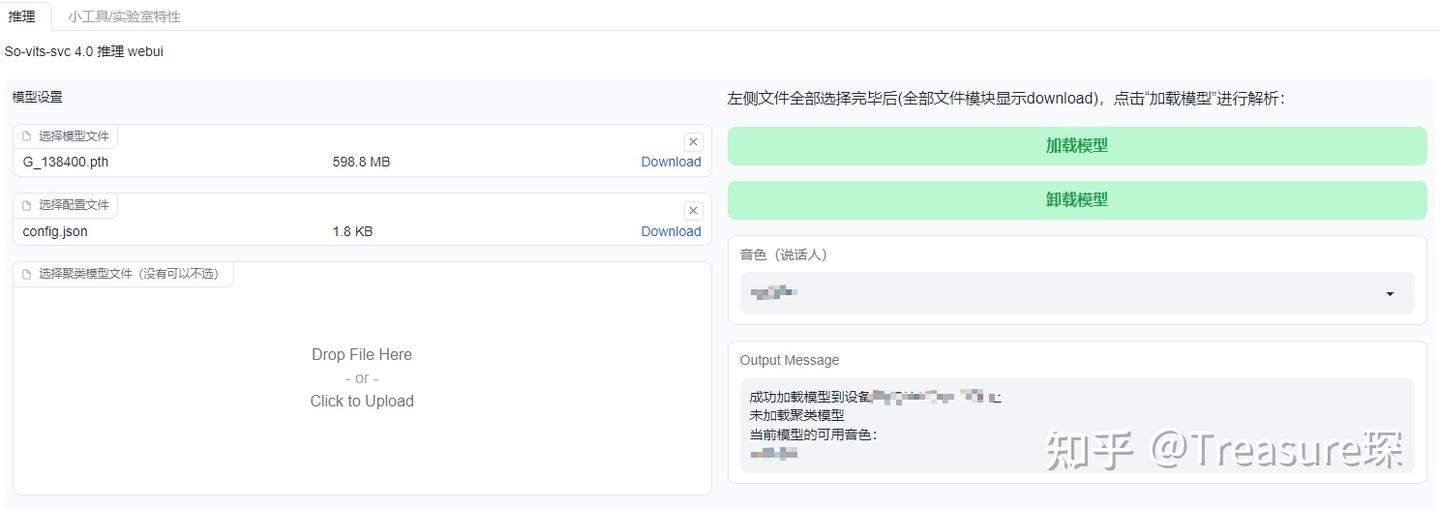
首先导入模型文件,模型文件所在位置:.\so-vits-svc\logs\44k\G_xxxx.pth
然后导入配置文件,配置文件所在位置:.\so-vits-svc\configs\config.json
导入这两个文件后,加载模型,如果成功加载,可以得到音色名称:
(2)导入歌曲并替换音色
将刚才准备的干净人声导入,点击音频转换即可得到转换后的音频:
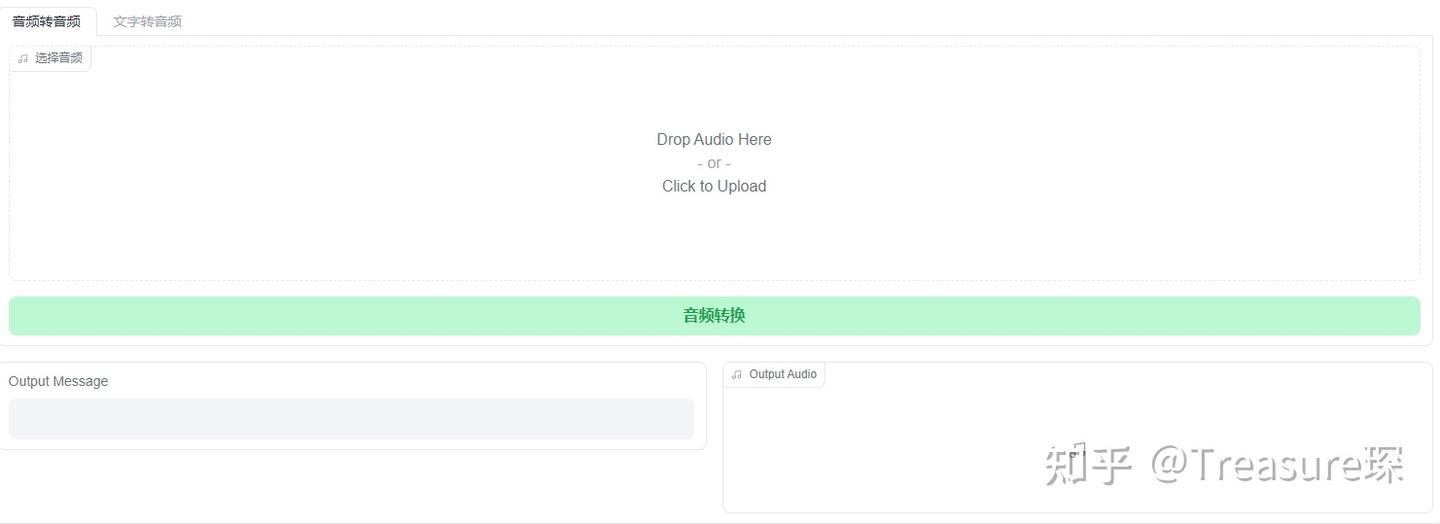
五、人声伴奏混合
得到转换后的人声音频后,需要把人声和伴奏混合,最简单的方法是利用格式工厂的音频混合功能:
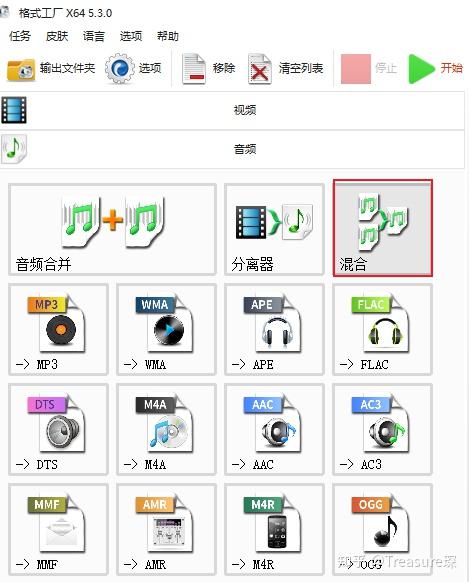
这种方法不能条件人声和伴奏的比例,如果想要更好地去混音,可以利用AU等专业的音乐处理软件。