分享两篇关于数据科学与机器学习趋势的文章,供大家参考。总结下来,最最重要的两大趋势:
实际应用中,小模型(Qwen-8B etc)将越来越受到关注
Agent和AutoML将越来越受到关注
1. Data Science in 2026: Is It Still Worth It?

Are you thinking about switching to Data Science in 2026?
If the answer is “yes,” this article is for you.
I’m Sabrine. I have spent the last 10 years working in the AI field across Europe—from big companies and startups to research labs. And if I had to start over again today, I would honestly still choose this field. Why?
For the same reasons that brought many of us here: the intellectual challenge, the impact you can have, the love for mathematics and code, and the possibility to solve real-life problems.
But looking toward 2026… is it still worth it?
If you scroll through LinkedIn, you will see two teams fighting: one saying “Data Science is dead,” and the other saying it is growing thanks to the AI trend.
When I look around me, I personally think we will always need computational skills. We will always need people who can understand data and help make decisions. Numbers have always been everywhere, and why would they disappear in 2026?
However, the market has changed. And to navigate it now, you need good guidance and clear information.
In this article, I’ll share my own experience from working in research and industry, and from mentoring more than 200 Data Scientists over the last few years.
So what is happening in the market now?
I will be honest and not sell you any dream about it.
The goal is not to introduce biases, but to give you enough information to make your own decision.
Is the Data Science job family broader than ever?
Source: pixabay (Kanenori)

One of the biggest mistakes of junior Data Scientists is thinking Data Science is one single job.
In 2026, Data Science is a large family of roles. Before writing a single line of code, you need to understand where you fit.
People are fascinated by AI: how ChatGPT talks, how Neuralink stimulates brains, and how algorithms affect health and security. But let’s be honest: not all aspiring Data Scientists will build these types of projects.
These roles need strong applied math and advanced coding skills. Does that mean you will never reach them? No. But they are often for people with PhDs, computational scientists, and engineers trained exactly for these niche jobs.
Let’s take a real example: a Machine Learning/Data Scientist job offer I saw today (Nov 27) at a GAFAM company.
Screenshot taken by the author

If you look at the description, they ask for:
Patents
First-author publications
Research contributions
Does everyone interested in Data Science have a patent or a publication? Of course not.
This is why you must avoid moving blindly.
If you just finished a bootcamp or are early in your studies, applying for jobs that explicitly require research publications will only bring frustration. These very specialized jobs are usually for people with advanced academic backgrounds (PhD, post-doc, or computational engineering).
My advice: be strategic. Focus on roles that match your skills.
Don’t waste time applying everywhere.
Use your energy to build a portfolio that aligns with your goals.
You must understand the different sub-fields inside Data Science and choose what fits your background. For example:
Product Data Analyst / Scientist: product lifecycle and user needs
Machine Learning Engineer: deploying models
GenAI Engineer: works on LLMs
Classic Data Scientist: inference and prediction
If you look at a Product Data Scientist role at Meta, the technical level is often more adapted to most Data Scientists on the market compared to a Core AI Research Engineer or Senior Data Scientist role.
These roles are more realistic for someone without a PhD.

Screenshot taken by the author

Even if you don’t want to work at GAFAM, keep in mind:
They set the direction. What they require today becomes the norm everywhere else tomorrow.
Now, how about coding and math in 2026?
Source: pixabay (NoName_13)
Here is a controversial but honest truth for 2026: Analytical and mathematical skills matter more than just coding.
Why? Almost every company now uses AI tools to help write code. But AI cannot replace your ability to:
understand trends
explain where the value comes from
design a valid experiment
interpret a model in a real context
Coding is still important, but you cannot be a “General Importer”—someone who only imports sklearn and runs .fit() and .predict().
Very soon, an AI agent may do that part for us.
But your math and analytical skills are still important, and will always be.
A simple example:
You can ask an AI: “Explain PCA like I’m 2 years old.”
But your real value as a Data Scientist comes when you ask something like:
“I need to optimize the water production of my company in a specific region. This region is facing issues that make the network unavailable in specific patterns. I have hundreds of features about this state of the network. How can I use PCA and be sure the most important variables are represented in the PC I’m using?”
-> This human context is your value.
-> AI writes the code.
-> You bring the logic.
And how about the Data Science toolbox?
Let’s start with Python. As a programming language with a large data community, Python is still essential and probably the first language to learn as a future Data Scientist.
The same for Scikit-learn, a classic library for machine learning tasks.
Screenshot taken by the author
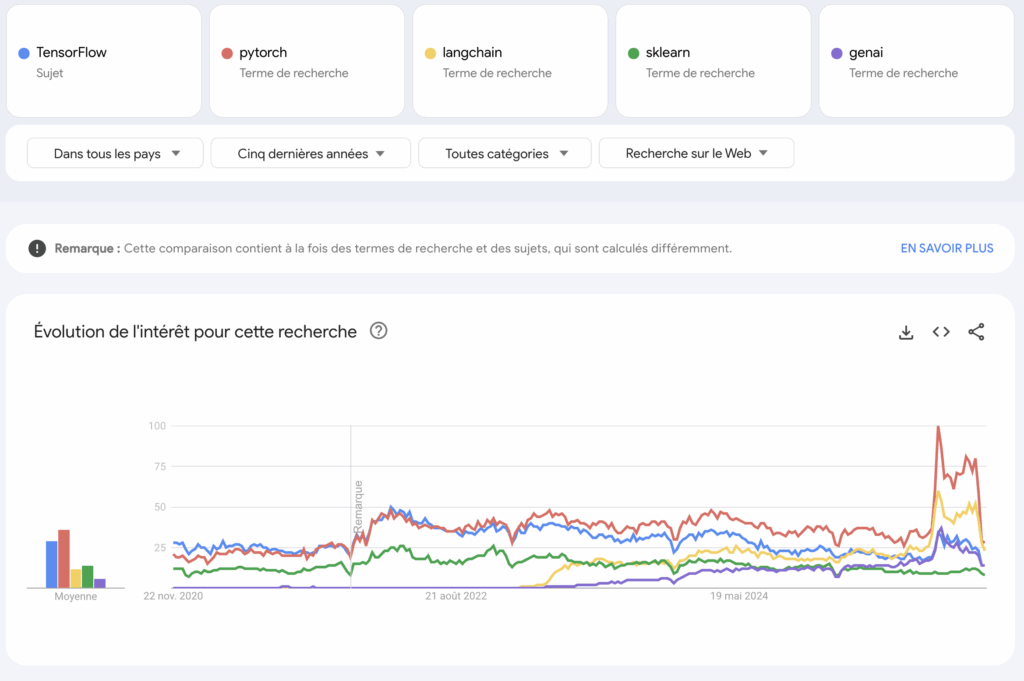
We can also see on Google Trends (late 2025) that:
PyTorch is now more popular than TensorFlow
GenAI integration is growing much faster than classical libraries
Data Analyst interest stays stable
Data Engineer and AI Specialist roles interested more people than general Data Scientist roles
Don’t ignore these patterns; they are very helpful for making decisions.
You need to stay flexible.
If the market wants PyTorch and GenAI, don’t stay stuck with only Keras and old NLP.
And what about the new stack for 2026?
This is where the 2026 roadmap is different from 2020.
To get hired today, you need to be production-ready.
Version Control (Git): You will use it daily. And to be honest, this is one of the first skills you need to learn at the beginning. It helps you organize your projects and everything you learn.
Whether you are starting a Master’s program or beginning a bootcamp, please don’t forget to create your first GitHub repository and learn a few basic commands before going further.
AutoML: Understand how it works and when to use it. Some companies use AutoML tools, especially for Data Scientists who are more product-oriented.
The tool I have in mind, and that you can access for free, is Dataiku. They have a great academy with free certifications. It is one of the AutoML tools that has exploded in the market in the last two years.
If you don’t know what AutoML is: it is a tool that lets you build ML models without coding. Yes, it exists.
Remember what I said earlier about coding? This is one of the reasons why other skills are becoming more important, especially if you are a product-oriented Data Scientist.
MLOps: Notebooks are not enough anymore. This applies to everyone. Notebooks are good for exploration, but if at some point you need to deploy your model in production, you must learn other tools.
And even if you don’t like data engineering, you still need to understand these tools so you can communicate with data engineers and work together.
When I talk about this, I think about tools like Docker (check out my article), MLflow (link here), and FastAPI.
LLMs and RAG: You don’t need to be an expert, but you should know the basics: how the LangChain API works, how to train a small language model, what RAG means, and how to implement it. This will really help you stand out in the market and maybe move further if you need to build a project that involves an AI Agent.
Portfolio: Quality over quantity
In this fast and competitive market, how can you prove you can do the job? I remember I’ve written an article about how to create a portfolio 2 years ago and what I’m going to say here can look a bit contradictory, but let me explain. Before ChatGPT and AI tools flooded the market, having a portfolio with a bunch of projects to show your different skills like data cleaning and data processing was very important, but today all these basic steps are often done using AI tools that are ready for that, so we will focus more on building something that will make you different and make the recruiter want to meet you.
I would say: “Avoid burnout. Build smart.”
Don’t think you need 10 projects. If you’re a student or a junior, one or two good projects are enough.
Take advantage of the time you have during your internship or your final bootcamp project to build it. Please don’t use simple Kaggle datasets. Look online: you can find a huge amount of real use-case data, or research datasets that are more often used in industry and labs to build new architectures.
If your goal is not to go deep into the technical side, you can still show other skills in your portfolio: slides, articles, explanations of how you thought about the business value, what results you got, and how these results can be used in reality. Your portfolio depends on the job you want.
If your goal is more math-oriented, the recruiter will probably want to see your literature review and how you implemented the latest architecture on your data.
If you are more product-oriented, I would be more interested in your slides and how you interpret your ML results than in the quality of your code.
If you are more MLOps-oriented, the recruiter will look at how you deployed, monitored, and tracked your model in production.
To finish, I want to remind you that the market is changing fast, but it is not the end of Data Science. It just means you need to be more aware of where you fit, what skills you want to grow, and how you present yourself.
Keep learning, and build a portfolio that truly reflects who you are. You will find your place
If you enjoyed this article, feel free to follow me on LinkedIn for more honest insights about AI, Data Science, and careers.
LinkedIn: Sabrine Bendimerad
Medium: https://medium.com/@sabrine.bendimerad1
2. What's Trending in Data Science and ML Preparing for 2026
Was it time well spent?
Last week, I attended the Nordic DS/ML Summit 2025 in Stockholm 🇸🇪, a two-day event bringing together industry leaders, researchers, and practitioners to share how data science and machine learning are evolving.
The lineup included big names like Meta, NVIDIA, and Google DeepMind.
And of course, the hottest topic was….🥁… Agentic AI (no surprise there)
{kind=link}

Panel discussion on the topic of “Building the Future of AI: Scaling Foundation Models and Agents for Real-World Applications“. Image by NDSML.
This photo is from an interesting panel discussion featuring:
Chi Wang, Senior Staff Research Scientist at Google DeepMind and Founder of AutoGen (now AG2)
Rohit Patel, Director at Meta Superintelligence Labs
Sepideh Pashami, Acting Director of Data Analysis at RISE Research Institutes of Sweden
So I would say yes, it was definitely time well spent!
Today, I’m going to break down my learnings, the key trends I observed, and, towards the end, tie it all back to what we, Data Scientists, should pay attention to as we enter 2026.
Let’s get to it!
Three key trends that stood out (to me) the most

Cartoon depicting the motivation behind AutoGen. Image by AutoGen.
These are the trends that stuck with me during the event, and that, in some way or another, have gained enough momentum to be worth following closely.
1). From traditional analytics to agentic analytics
We’re entering a new phase of analytics. One where dashboards and static reports aren’t enough anymore.
I foresee this will become an even bigger topic by the beginning of 2026.
The focus will be on creating more dynamic systems that can speed up the path from data to insight, making analytics more adaptive and less dependent on manual exploration, which many are starting to refer to as Agentic Analytics.
💡 One thing is clear, the companies who will lead the way in this Agentic Analytics shift, will be those who have the foresight to build a strong data engineering foundation and invest in their semantic modeling. That’s ultimately what will enable AI agents to interact with their data in meaningful ways. More on this later in the article.
2). Small language models are the next big thing
Small language models (sLMs) are becoming surprisingly capable.
Models like Phi-3, Mistral, and Llama 3 8B show that you don’t need massive infrastructure to get strong performance. With some fine-tuning, they can even outperform larger models on focused tasks.
💡 For developers and smaller teams, this also means we can now run fast, private, and low-cost models, on a regular laptop or even a phone.
3). The rise of specialized multi-agent systems
A big theme that kept coming up was the move toward hierarchical multi-agent systems. Instead of relying on a single agent to handle an entire workflow, newer architectures now use an orchestrator agent that breaks tasks into smaller pieces and delegates them to specialized sub-agents.
Each sub-agent focuses on one tiny, well-defined task, like cleaning data, summarizing findings, or generating code, and becomes extremely good at that single thing. Together, they form a coordinated system that’s faster, cheaper, and more reliable than one general-purpose agent working alone.
💡 This “divide and conquer” approach also opens the door for sLMs to play a bigger role. Since each sub-agent only needs to handle a narrow task, even lightweight models can perform well when combined in a well-orchestrated system.
It’s a design pattern we’ll likely see more of as agentic systems mature and move into production use.
What should Data Scientists pay attention to?
My recommendation, especially to mid-senior data scientists who want to take the next leap in their career growth: Lead the way in the Agentic Analytics shift at your company.
From what I’ve seen, most organizations are still just waking up to this change.
That means you have a real opportunity to lead, whether it’s by championing modern enterprise tools that enable agentic analytics or by building your own agents that make analysis faster, more interactive, and closer to decision-making.
The people who learn to bridge that gap early, between AI agents and analytics, will be the ones shaping how Data Science is practiced in the next decade.
Five real-world agentic AI use cases in Data Science
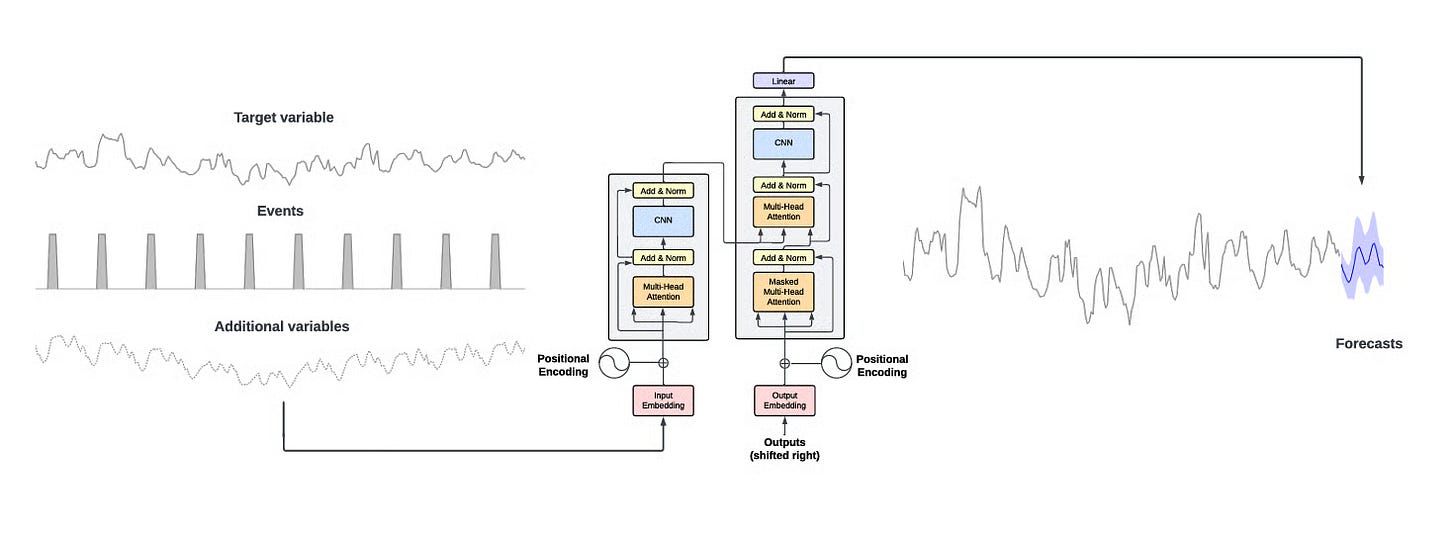
Diagram of how TimeGPT takes the historical values of the target values and additional exogenous variables as inputs to produce the forecasts. Image by TimeGPT.
These are some use cases where GenAI and Agentic AI are already starting to make an impact:
Conversational dashboards for fast insightsThink dashboards you can talk to, ask questions in plain English, and get instant summaries or visualizations. Power BI Copilot and Tableau Pulse are early examples, but the concept applies to any workflow where non-technical users need fast answers from data.
EDA and data cleaning agentsAI agents are starting to automate the time-consuming work of detecting outliers, normalizing data, and generating initial visualizations during EDA. Tools like Tableau’s Data Pro hint at how you can build agents to accelerate your data prep process.
Foundation models for analyticsInstead of training a new model for every metric or product, foundation models like TimeGPT are starting to handle forecasting, anomaly detection, and other analytic tasks straight from raw data. This makes advanced analytics more accessible, even for teams without deep expertise in time series or model building.
Agentic monitoring and proactive analyticsRather than waiting for a human to check a dashboard, agentic systems can watch KPIs, detect shifts, and trigger alerts or recommendations. Tableau Inspector and Adverity are pushing this, but it’s a pattern any analyst can explore with the right setup.
Multi-agent orchestration of the ML workflowPlatforms like causaLens are an example of what’s possible with AI agents that collaborate, some clean the data, others build models, and others explain results. It’s not just automation, it’s coordination, and it’s a glimpse of how future ML workflows could run.
🔑 Don’t ignore this: The Semantic Layer
I wanted to mention this concept again since I feel it might get overlooked by a lot of you reading this article, and that would be a BIG mistake.
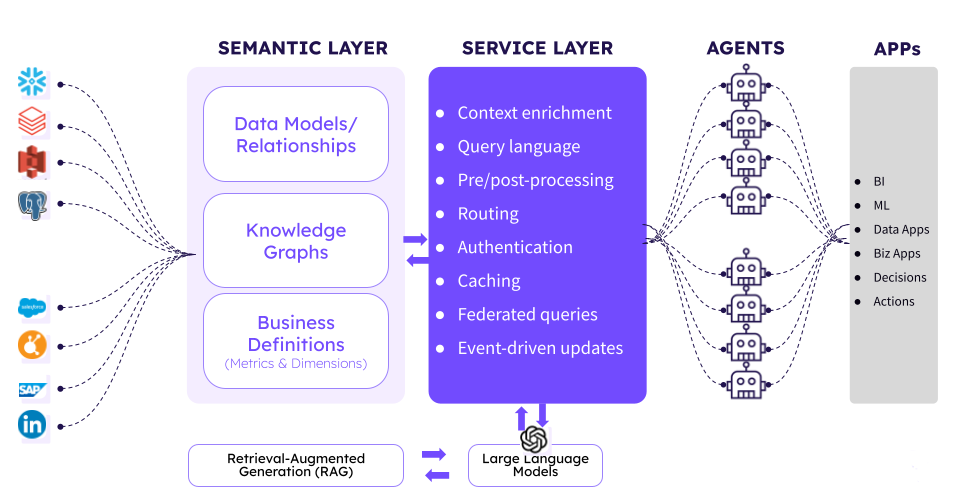{kind=link}
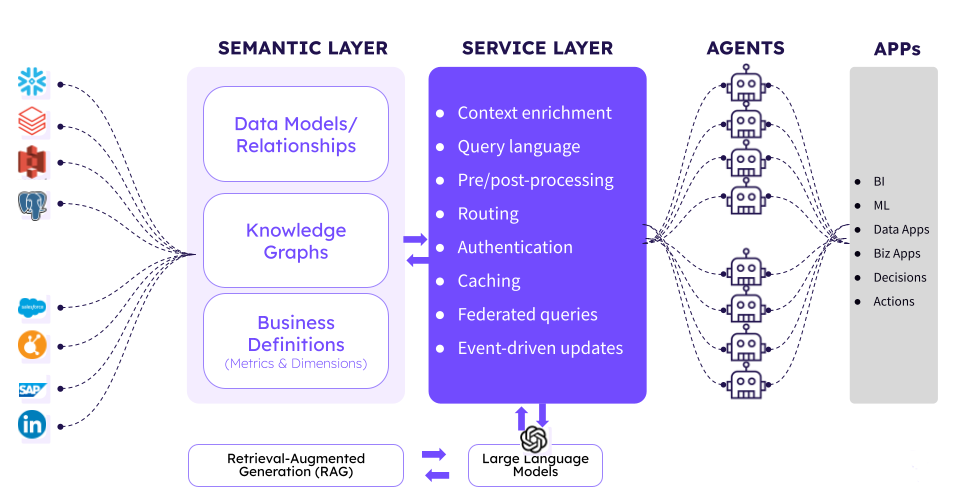
Semantic Layer architecture. Image by Tallius.
Over the past 6 months or so, I’ve been spending more time building my own AI workflows to optimise and automate much of my data science work. And recently, I deployed a talk-to-your-data Slackbot that is slowly redefining the meaning of self-serve analytics at my company.
One of the keys to the success of these tools has been defining the semantic layer.
📌 This is also why I’m teaching it to the 22 Data Scientists currently enrolled in my
The idea is simple: the semantic layer creates a shared definition of metrics and business logic so data scientists, stakeholders, and most importantly, AI agents, all work from the same source of truth.
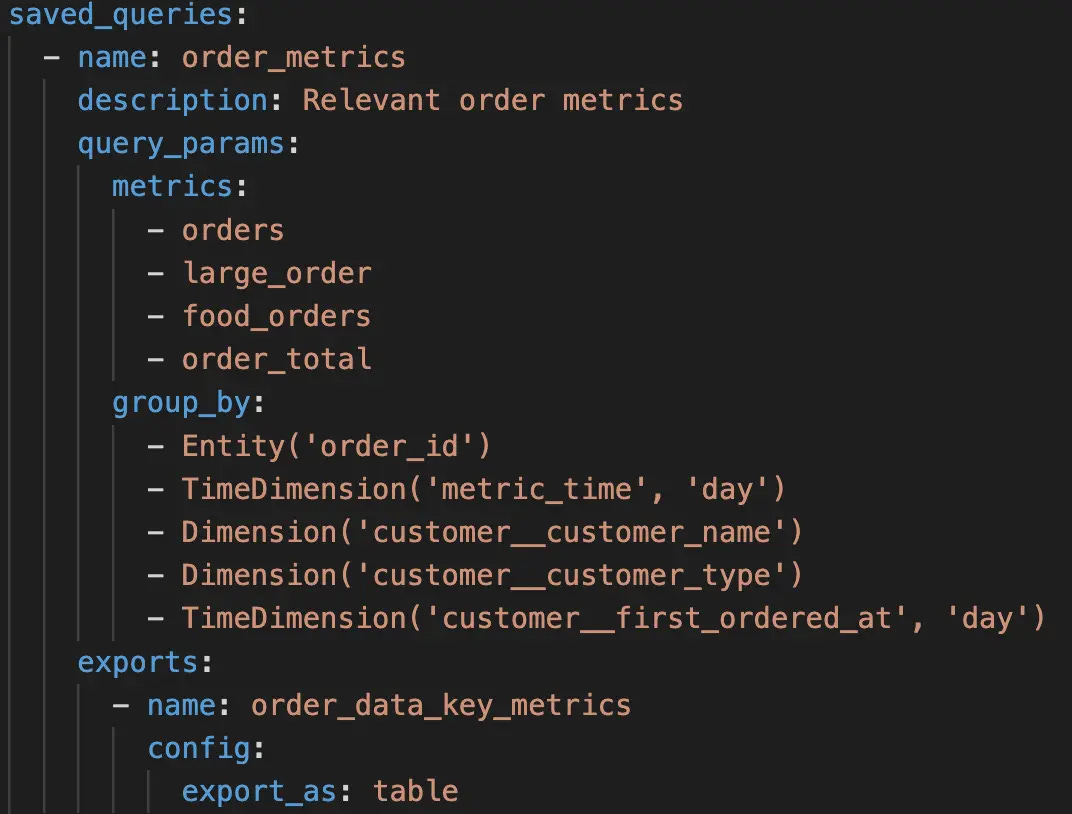{kind=link}
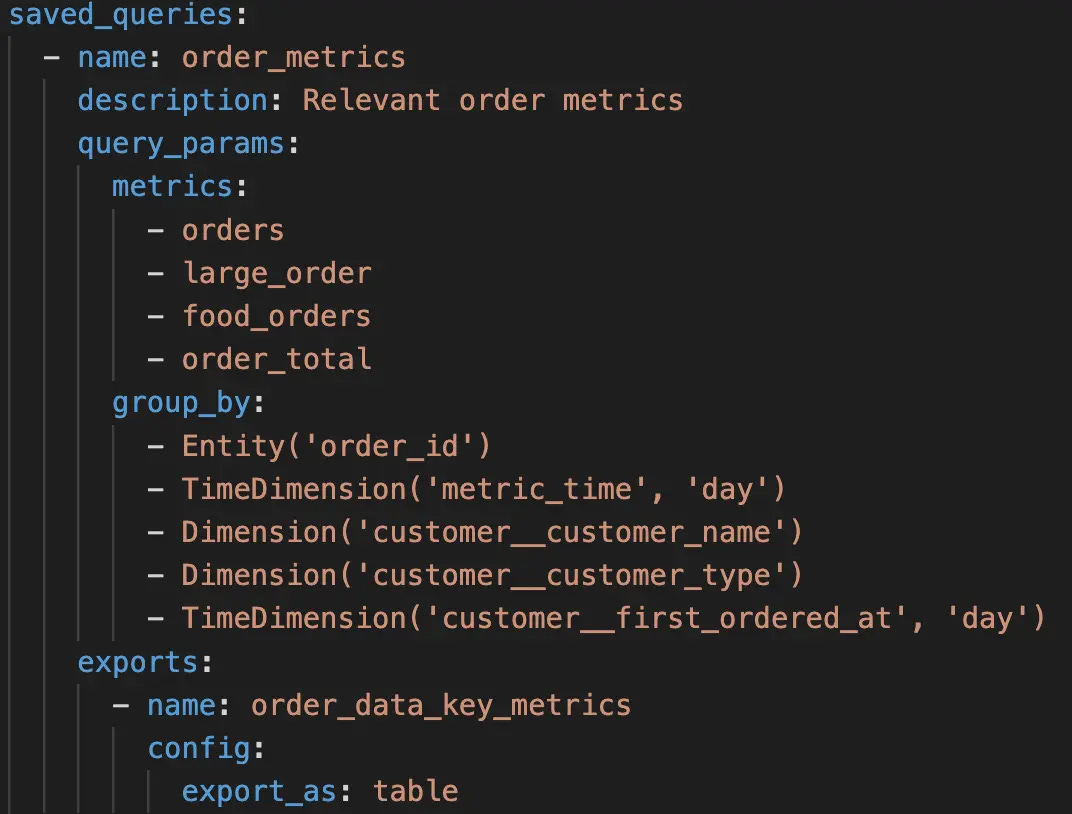
Example of a semantic layer YAML file. Image by dbt.
And believe me, you don’t need to be a data engineer to start building a semantic layer to enhance your AI agents.
POLL
Should I write an entire article on this topic?
Yes
96%
No, I’m good
4%
45 VOTES · POLL CLOSED
Honorable mentions
Here are some cool tools and products I didn’t get to cover, but thought deserved at least a quick mention:
Orion: An on-device autonomous agent that orchestrates your AI tools and runs locally for cross-platform automation.
AG2: Open-source framework (formerly AutoGen) for building and orchestrating multi-agent systems.
HP ZGX Nan AI Station: A nano AI workstation for prototyping and fine-tuning inference models of up to 200B parameters locally.
Closing thoughts
If there’s one thing this year’s summit made clear, it’s that the gap between AI research and real-world data science is closing faster than ever.
Agentic systems, small models, and better data foundations aren’t just trends; they’re signals that our field is evolving into something more intelligent.
For data scientists, this next phase isn’t about chasing every new tool that comes out. It’s about understanding the direction we’re heading and learning how to apply these ideas where they actually create impact.
If you do that, if you stay curious, experiment with these concepts, and think beyond your notebook, you won’t just keep up with the changes. You’ll help shape what data science looks like in 2026 and beyond.
A couple of other great resources:
🚀 Ready to take the next step? Build real
💼 Job searching?
🤖 Struggling to keep up with AI/ML?
Thank you for reading! I hope these insights give you a competitive advantage as we prepare to enter 2026.
- Andres Vourakis