1.概述
在音高及其Python实现一文 中,我们使用了简单的“观察法”来计算音高,这并不太难,但这并不有好而且费时费力,那么我们就想,如何通过分析和计算,使用算法来自动计算音高呢? 用算法让计算机自动抓取音高的过程,称为音高追踪(Pitch Tracking)。所得到的音高信息有如下一些应用: ·旋律识别(Melody Recognition):或称为“哼唱选歌”,也就是如何由使用者的哼唱,找出音乐资料库中间对应的歌。 ·汉语声调识别(Tone Recognition):辨识使用者讲一句话时,每一个字的声调(一声、二声、三声、四声等)。 ·语音合成韵律分析(Prosody Analysis)中的音高分析:如何在合成语音时,使用最自然的音高曲线。 ·语音评分中的音调评分(Intonation Assessment):如何评估使用者说话的语音,其音高曲线是否标准。 ·语音识别(Speech Recognition):我们可以使用语句的音高来提高语音辨识的正确率。 总而言之,音高追踪是语音信号处理中最基本也最重要的一个环节之一。
2.音高追踪的基本流程
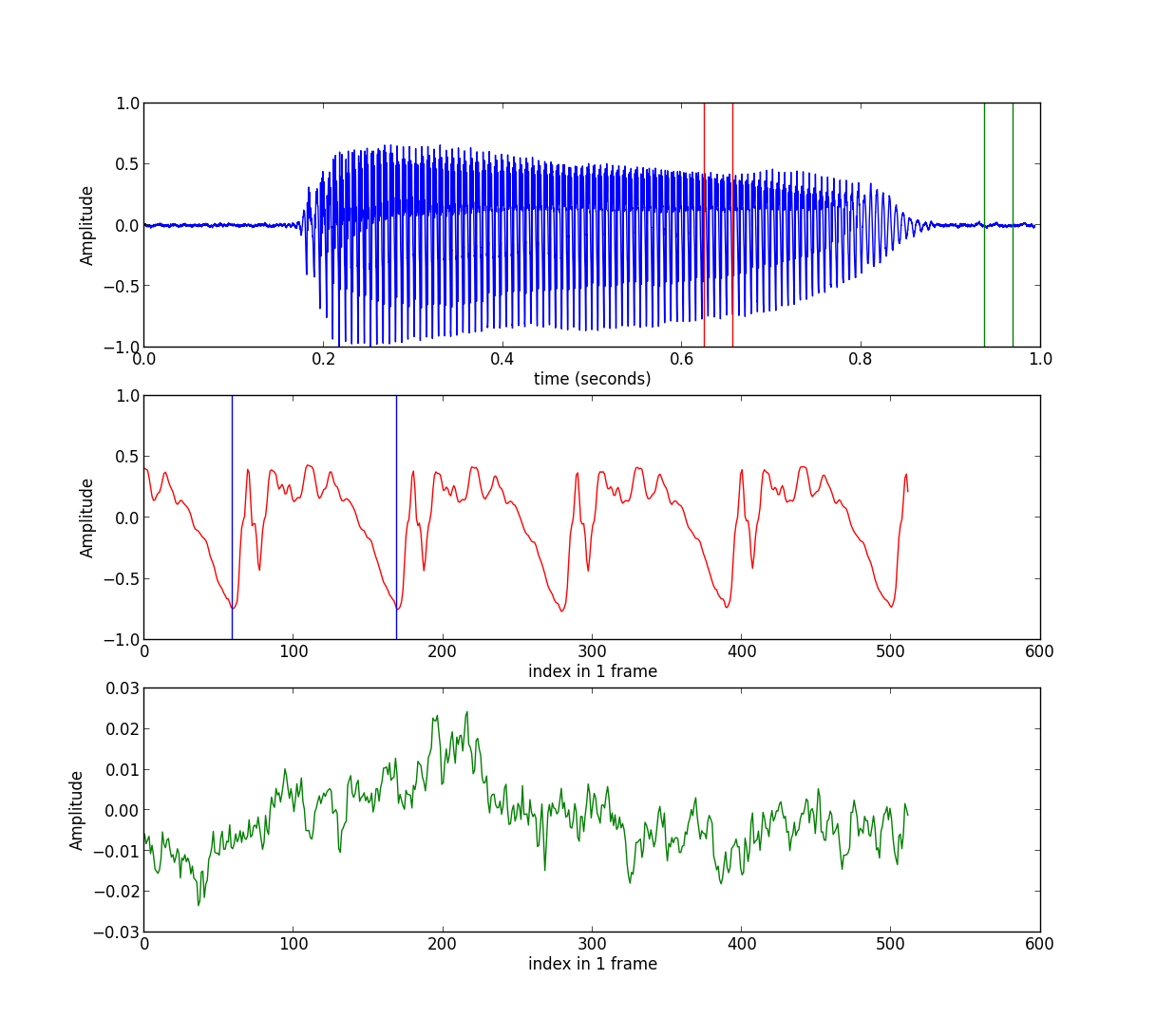
音高追踪的基本流程如下: (1)将整段音讯讯号切成音框(Frames),相邻音框之间可以重叠。 (2)算出每个音框所对应的音高。 (3)排除不稳定的音高值。(可由音量来筛选,或由音高值的范围来过滤。) (4)对整段音高进行平滑化,通常是使用「中位数滤波器」(Median Filters)。