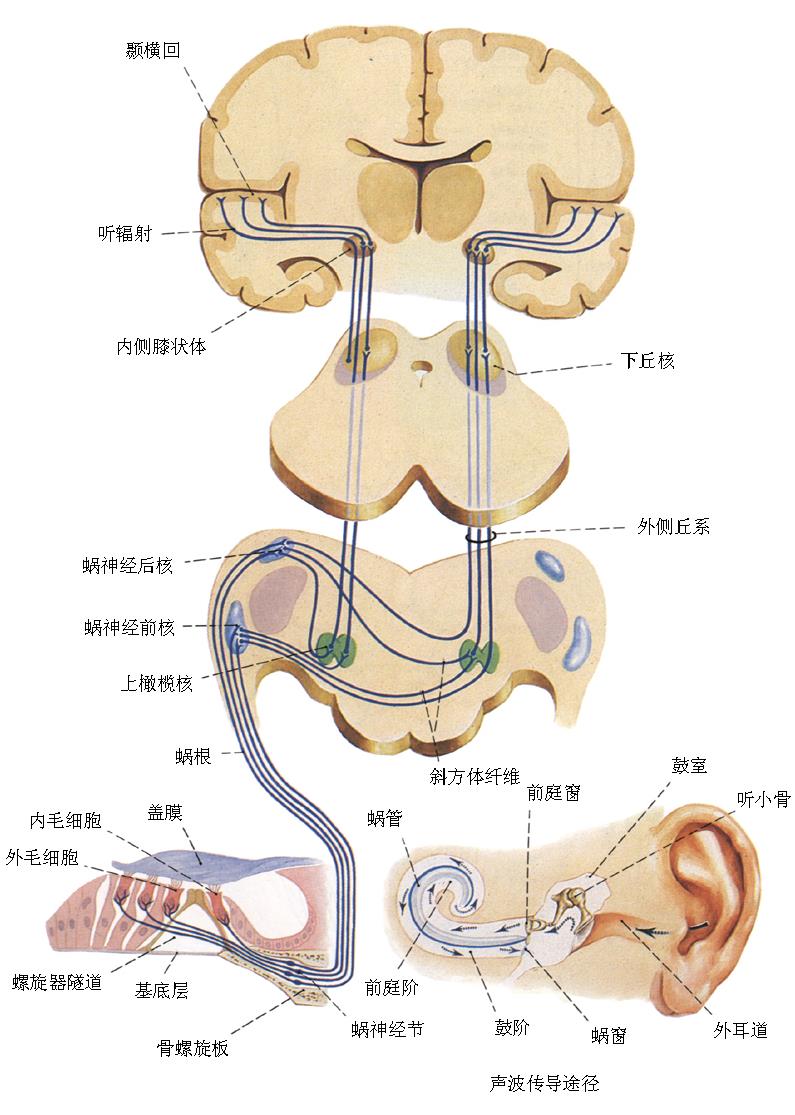
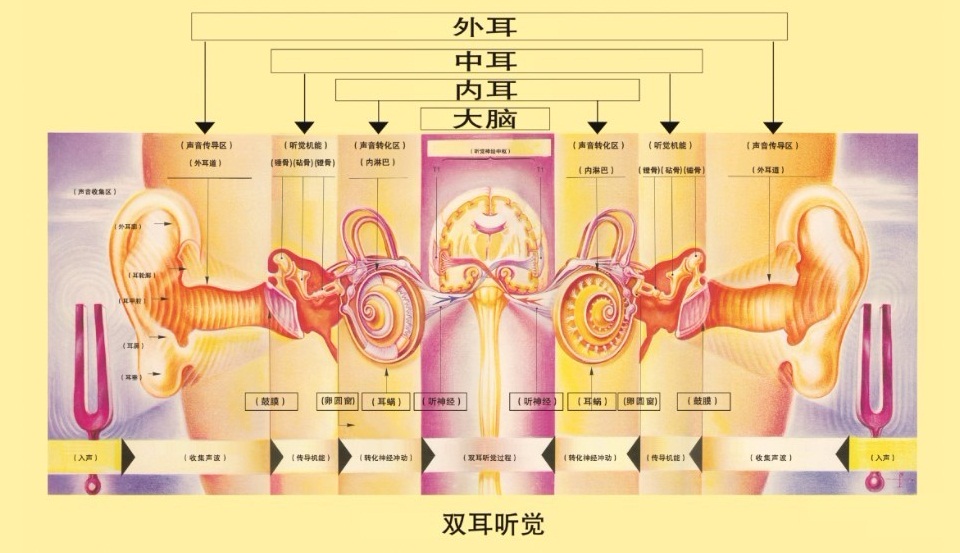
0.概述
以下是Wiki上对深度学习的下的定义: Deep learning refers to a sub-field of machine learning that is based on learning several levels of representations, corresponding to a hierarchy of features or factors or concepts, where higher-level concepts are defined from lower-level ones, and the same lower-level concepts can help to define many higher-level concepts.
深度学习就是学习多个级别的表示和抽象,帮助理解数据,如图像、声音和文本。深度学习的概念源于人工神经网络的研究, 含多隐层的多层感知器就是一种深度学习结构。那些涉及从输入产生输出的计算,我们可以用流程图来表示, 流程图的一个特殊的概念就是它的深度: 从输入到输出的路径的最长长度。传统的前馈神经网络可以理解为 深度等于层数(隐层数+1)的网络。深度学习通过组合低层特征形成更加抽象的高层表示(属性类别或特征), 以发现数据的分布式特征表示。
1.深度学习产生的背景
1.1深度不够的缺陷
在很多情况下,深度为2就已足以在给定精度范围内表示任何函数了,例如逻辑门、正常 神经元、sigmoid-神经元、SVM中的RBF(Radial Basis Function)等,但这样也有一个代价: 那就是图中需要的节点数会很多,这也就意味着当我们学习目标函数时,需要更多的计算 单元和更多的参数。理论结果显示,对于某一类函数,需要的参数的个数与输入的大小是 成指数关系的,逻辑门、正常神经元、RBF单元就属于这类。后来Hastad发现,当深度为d时, 这类函数可以用O(n)个节点(输入为n个)的神经网络有效表示,但当深度被限制为d-1时, 则需要有O(n2)个节点来表示。