
本次推文介绍用线性模型处理回归问题。从简单问题开始,先处理一个响应变量和一个解释变量的一元问题。然后,介绍多元线性回归问题(multiple linear regression),线性约束由多个解释变量构成。紧接着,介绍多项式回归分析(polynomial regression问题),一种具有非线性关系的多元线性回归问题。最后,介绍如果训练模型获取目标函数最小化的参数值。在研究一个大数据集问题之前,先从一个小问题开始学习建立模型和学习算法
本次推文介绍用线性模型处理回归问题。从简单问题开始,先处理一个响应变量和一个解释变量的一元问题。然后,介绍多元线性回归问题(multiple linear regression),线性约束由多个解释变量构成。紧接着,介绍多项式回归分析(polynomial regression问题),一种具有非线性关系的多元线性回归问题。最后,介绍如果训练模型获取目标函数最小化的参数值。在研究一个大数据集问题之前,先从一个小问题开始学习建立模型和学习算法
有这么一句话在业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。那特征工程到底是什么呢?顾名思义,其本质是一项工程活动,目的是最大限度地从原始数据中提取特征以供算法和模型使用。通过总结和归纳,人们认为特征工程包括以下方面:

选自Medium,作者:Leon Fedden
机器之心编译,参与:Nurhachu Null、刘晓坤
这篇文章基于 GitHub 中探索音频数据集的项目。本文列举并对比了一些有趣的算法,例如 Wavenet、UMAP、t-SNE、MFCCs 以及 PCA。此外,本文还展示了如何在 Python 中使用 Librosa 和 Tensorflow 来实现它们,并用 HTML、Javascript 和 CCS 展示可视化结果。
Jupyter Notebook:https://gist.github.com/fedden/52d903bcb45777f816746f16817698a0
浏览器可视化代码:https://github.com/fedden/umap_tsne_embedding_visualiser
作者希望能和我们分享两个代码库。第一个是用来制作这篇文章的 notebook,它不像我通常喜欢的那样精美,但是花了很长时间,读者可以随意使用并扩展它。
此外,作者也上传了浏览器中的这些可视化代码到 github 上。他使用 Material Design Lite 库以相对简洁的方式创建用户界面,用 THREE.js 库来快速绘制数据并进行优化,还使用 webaudiox.js 可以让音频生成得更容易。
文章从用户生命周期的四个阶段并贴合活跃这一维度,罗列了Pinterest内部关注的20多项指标。从Pinterest我们可以延伸至内容类产品来看待这些指标,因为和电商、互金等产品相比,活跃的波动对内容类产品有着更直接的影响。为了便于理解,文章最终提炼出了19项指标并部分添加了描述和解读,供参考。

文章内容可能会相对比较多,读者可以点击上方目录,直接阅读自己感兴趣的章节。
关于xgboost的原理网络上的资源很少,大多数还停留在应用层面,本文通过学习陈天奇博士的PPT、论文、一些网络资源,希望对xgboost原理进行深入理解。(笔者在最后的参考文献中会给出地址)
说到xgboost,不得不说gbdt,两者都是boosting方法(如图1所示),了解gbdt可以看我这篇文章 地址。

FM和FFM模型是最近几年提出的模型,凭借其在数据量比较大并且特征稀疏的情况下,仍然能够得到优秀的性能和效果的特性,屡次在各大公司举办的CTR预估比赛中获得不错的战绩。美团点评技术团队在搭建DSP的过程中,探索并使用了FM和FFM模型进行CTR和CVR预估,并且取得了不错的效果。本文旨在把我们对FM和FFM原理的探索和应用的经验介绍给有兴趣的读者。
在计算广告领域,点击率CTR(click-through rate)和转化率CVR(conversion rate)是衡量广告流量的两个关键指标。准确的估计CTR、CVR对于提高流量的价值,增加广告收入有重要的指导作用。预估CTR/CVR,业界常用的方法有人工特征工程 + LR(Logistic Regression)、GBDT(Gradient Boosting Decision Tree) + LR[1][2][3]、FM(Factorization Machine)[2][7]和FFM(Field-aware Factorization Machine)[9]模型。在这些模型中,FM和FFM近年来表现突出,分别在由Criteo和Avazu举办的CTR预测竞赛中夺得冠军[4][5]。

很多朋友很想知道神策分析(Sensors Analytics)是如何实现在每天十亿级别数据的情况下可以做到秒级导入和秒级查询,是如何做到不需要预先指定指标和维度就能实现多维查询的。今天正好在这篇文章里面,和大家交流一下我们的技术选型与具体的架构实现,希望能够对大家有所启发。
当然,脱离客户需求谈产品设计,不太现实;而脱离产品设计,纯粹谈技术选型与架构实现,也不现实。因此,我们首先会跟大家探讨一下神策分析从产品角度,是如何从客户需求抽象产品设计的,而产品设计,又是如何确定我们的技术选型。然后,我们则会从产品的整体架构出发,逐步介绍每一个模块和子系统的具体实现。
Hive是基于Hadoop平台的,它提供了类似SQL一样的查询语言HQL。有了Hive,如果使用过SQL语言,并且不理解Hadoop MapReduce运行原理,也就无法通过编程来实现MR,但是你仍然可以很容易地编写出特定查询分析的HQL语句,通过使用类似SQL的语法,将HQL查询语句提交Hive系统执行查询分析,最终Hive会帮你转换成底层Hadoop能够理解的MR Job。
对于最基本的HQL查询我们不再累述,这里主要说明Hive中进行统计分析时使用到的JOIN操作。在说明Hive JOIN之前,我们先简单说明一下,Hadoop执行MR Job的基本过程(运行机制),能更好的帮助我们理解HQL转换到底层的MR Job后是如何执行的。我们重点说明MapReduce执行过程中,从Map端到Reduce端这个过程(Shuffle)的执行情况,如图所示(来自《Hadoop: The Definitive Guide》):

精准化营销一直以来都是互联网营销业务在细分市场下快速获取用户和提高转化的利器。在移动互联网爆发的今天,数据量呈指数增长,如何在移动和大数据场景下用数据驱动进行精准营销,从而提高营销效能,成为营销业务部门的主要挑战之一,同时也是大数据应用的一个重要研究方向。本文通过数据体系架构和技术实现案例,分享美团大众点评数据应用团队在这个方向上的一些尝试和实践经验。
在介绍数据体系和框架前,为了方便大家理解,先简单阐述一下O2O营销的基本组成:O2O营销是由营销发生的渠道(站内,站外)与营销的主题业务(流量,交易)两个维度组成的,其中产生了多种营销的形态,如精准化用户营销活动、DSP的精准投放、渠道价值排名和反作弊等,数据分析和挖掘在这些环节都能发挥很大的价值。本文主要阐述站内的精准化用户营销活动。
一个站内用户运营活动的生命周期大概可以归纳为:确定目标、选取活动对象、设计活动方案、活动配置与上线、线上精准营销与动态优化以及效果监控与评估六个环节。如下图所示。

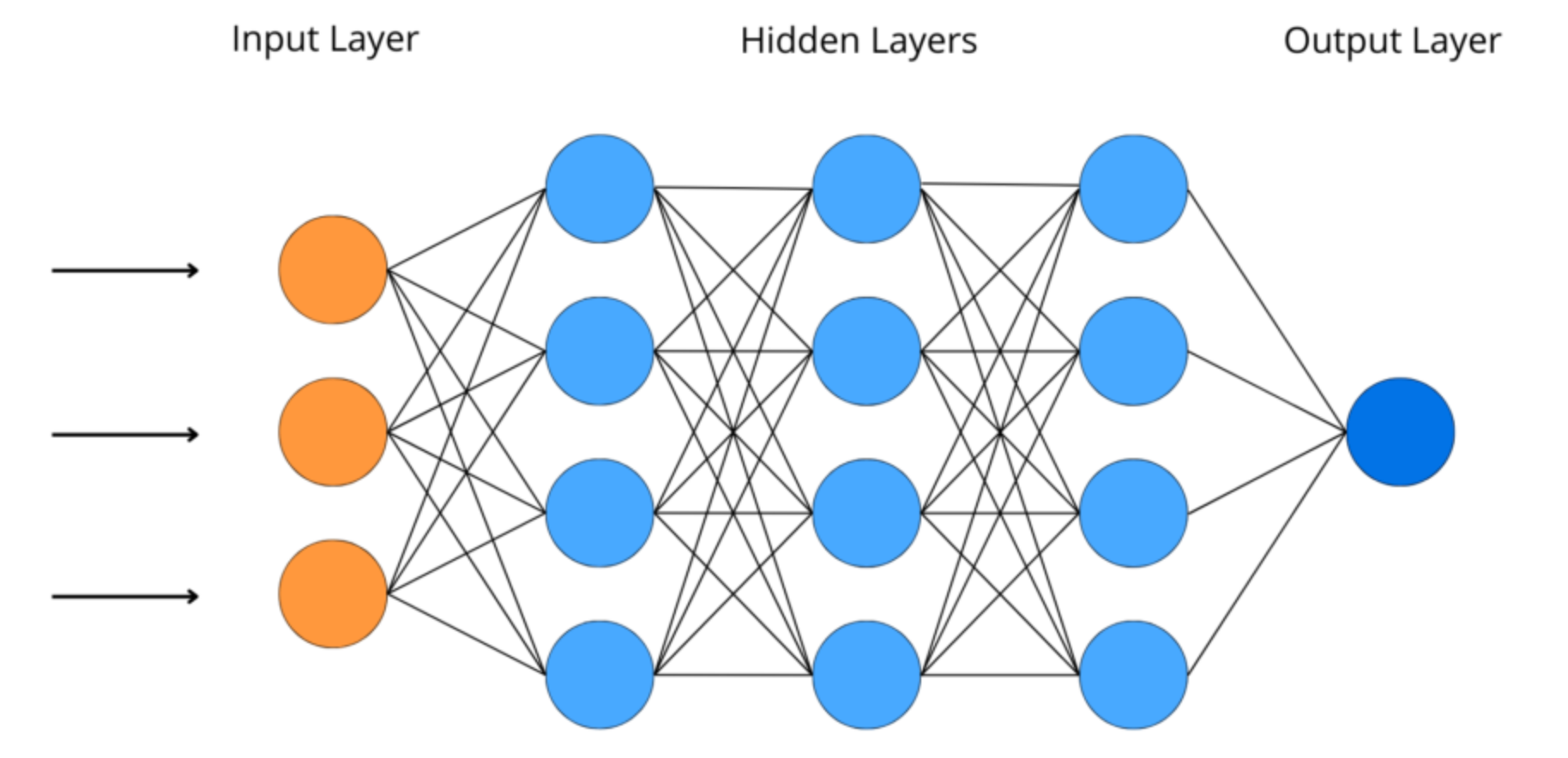
一般认为,增加隐层数可以降低网络误差(也有文献认为不一定能有效降低),提高精度,但也使网络复杂化,从而增加了网络的训练时间和出现“过拟合”的倾向。一般来讲应设计神经网络应优先考虑3层网络(即有1个隐层)。一般地,靠增加隐层节点数来获得较低的误差,其训练效果要比增加隐层数更容易实现。对于没有隐层的神经网络模型,实际上就是一个线性或非线性(取决于输出层采用线性或非线性转换函数型式)回归模型。因此,一般认为,应将不含隐层的网络模型归入回归分析中,技术已很成熟,没有必要在神经网络理论中再讨论之。