音色(Timbre)
音色是一个很模糊的概念,它泛指语音的内容,例如“天书”这两个字的发音,虽然都是一声(即他们的音高应该是相同或接近的), 但由于音色不同,我们可以分辨这两个音。直觉而言,音色的不同,意味着基本波形的不同,因此我们可以用基本周期的波形来代表音色。
若要从基本周期的波形来直接分析音色是一件很困难的事情。通常我们的做法是将每一个帧进行频谱分析(Spectral Analysis),算出一个 帧如何分解为不同频率的分量,然后才能进行对比或分析。在频谱分析中,最常用的方法就是快速傅里叶变换(Fast Fourier Transform,FFT), 这是一个相当常用的方法,可以讲在时域(Time Domain)的信号转换成频域(Frequency Domain)的信号,并进而知道每个频率的信号强度。
语谱图(Spectrogram)就是语音频谱图,一般是通过处理接收的时域信号得到频谱图,因此只要有足够时间长度的时域信号就可以(时间长度 为保证频率分辨率)。专业点讲,语谱图就是频谱分析视图,如果针对语音数据的话,叫语谱图。语谱图的横坐标是时间,纵坐标是频率,坐标点 值为语音数据能量,因而语谱图很好的表达了语音的音色随时间变化的趋势。有些经验丰富的人能够通过看语谱图而知道对应的语音信号的内容, 这种技术成为Spectrogram Reading。
Python绘制语谱图
如果是用Matlab,绘制语谱图并不难,网上资料也一堆一堆的。但是,如果要想用Python来绘制呢?网上相关资料很少很少,万幸中找到了参考[4], 但是,[4]中提供的程序是不能运行的,还需要安装几个库,特别是Audiolab这个,折腾了我好半天,最终安装了,但运行时发现这个audiolab根本无法 import进来,因为ms与numpy的版本有冲突,出现了什么“numpy.dtype does not appear to be the correct type object”,弄了好半天也没有解决, 后来才发现其实不需要audiolab也可以的,因为其实audiolab只是读取不同格式(扩展名)的语音文件的一个lib而已,并不涉及到绘制语谱图的东西。
闲话少说了,上代码吧,其实看看这代码也挺简单的,就调一个matplotlib.pyplot.specgram()就可以了。 ``` py3 import wave import numpy as np import matplotlib.pyplot as plt fw = wave.open('aeiou.wav','r') soundInfo = fw.readframes(-1) soundInfo = np.fromstring(soundInfo,np.int16) f = fw.getframerate() fw.close() plt.subplot(211) plt.plot(soundInfo) plt.ylabel('Amplitude') plt.title('Wave from and spectrogram of aeiou.wav') plt.subplot(212) plt.specgram(soundInfo,Fs = f, scale_by_freq = True, sides = 'default') plt.ylabel('Frequency') plt.xlabel('time(seconds)') plt.show() ```
程序运行的效果如下图:
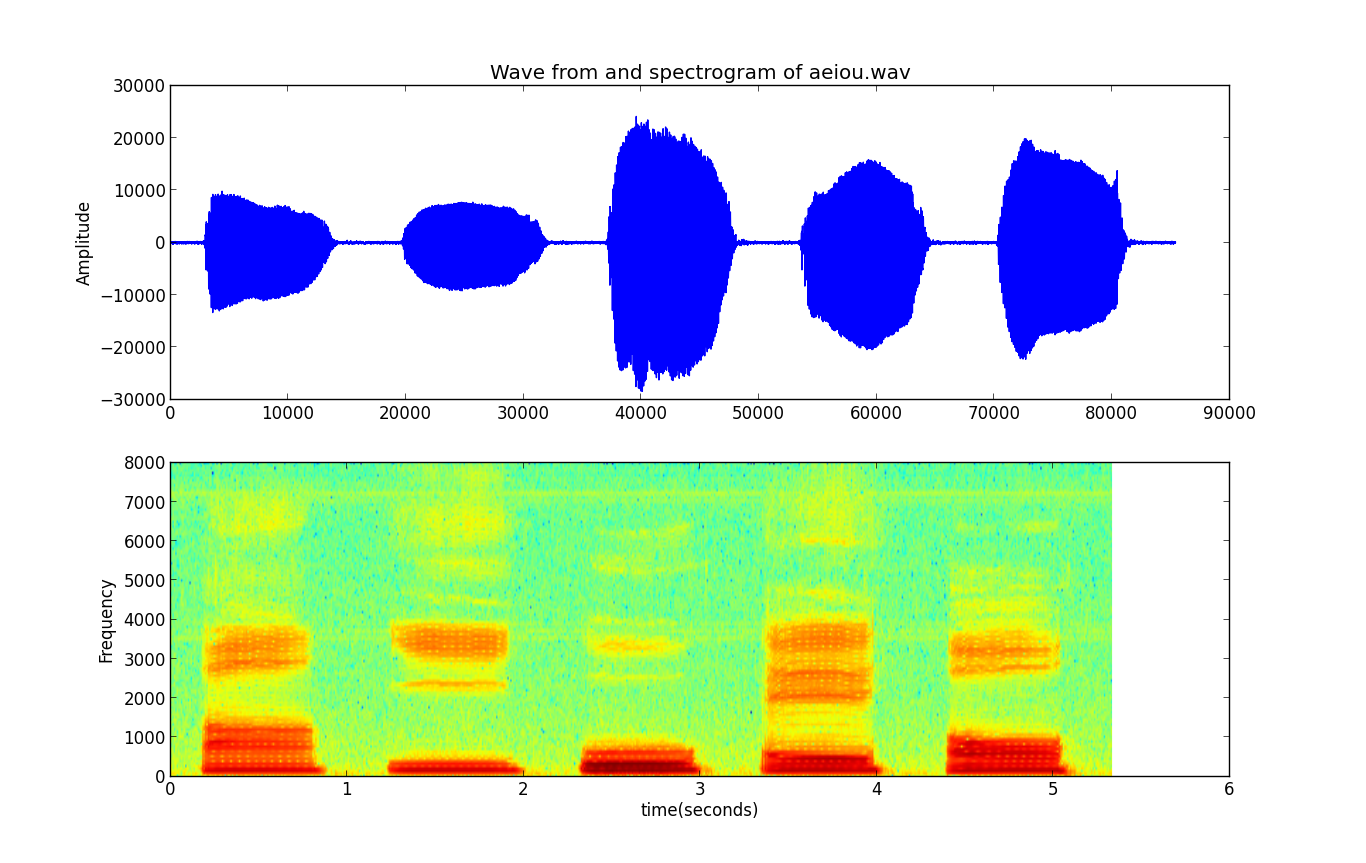
另外,就是关于这个语谱图具体是如何绘制的,这一点涉及到FFT和短时能量的计算,短时能量在前文中 已经讲过了,这里不再赘述。关于FFT将在后续文章中讨论。
参考(References)
[1]Timbre (音色): http://neural.cs.nthu.edu.tw/jang/books/audiosignalprocessing/basicFeatureTimber.asp?title=5-5 [2]Wiki - 音色: http://zh.wikipedia.org/wiki/音色 [3]语谱图: http://blog.csdn.net/wuxiaoer717/article/details/6941339 [4]How to plot spectrogram with Python:http://jaganadhg.freeflux.net/blog/archive/2009/07/23/how-to-plot-spectrogram-with-python.html