端点检测
端点检测(End-Point Detection,EPD)的目标是要决定信号的语音开始和结束的位置,所以又可以称为Speech Detection或Voice Activity Detection(VAD)。 端点检测在语音预处理中扮演着一个非常重要的角色。
常见的端点检测方法大致可以分为如下两类: (1)时域(Time Domain)的方法:计算量比较小,因此比较容易移植到计算能力较差的嵌入式平台 (a)音量:只使用音量来进行端检,是最简单的方法,但是容易对清音造成误判。另外,不同的音量计算方法得到的结果也不尽相同,至于那种方法更好也没有定论。 (b)音量和过零率:以音量为主,过零率为辅,可以对清音进行较精密的检测。 (2)频域(Frequency Domain)的方法:计算量相对较大。 (a)频谱的变化性(Variance):有声音的频谱变化较规律,可以作为一个判断标准。 (b)频谱的Entropy:有规律的频谱的Entropy一般较小,这也可以作为一个端检的判断标准。
下面我们分别从这两个方面来探讨端检的具体方法和过程。
时域的端检方法
时域的端检方法分为只用音量的方法和同时使用音量和过零率的方法。只使用音量的方法最简单计算量也最小,我们只需要设定一个音量阈值,任何音量小于该阈值的帧 被认为是静音(silence)。这种方法的关键在于如何选取这个阈值,一种常用的方法是使用一些带标签的数据来训练得到一个阈值,使得误差最小。
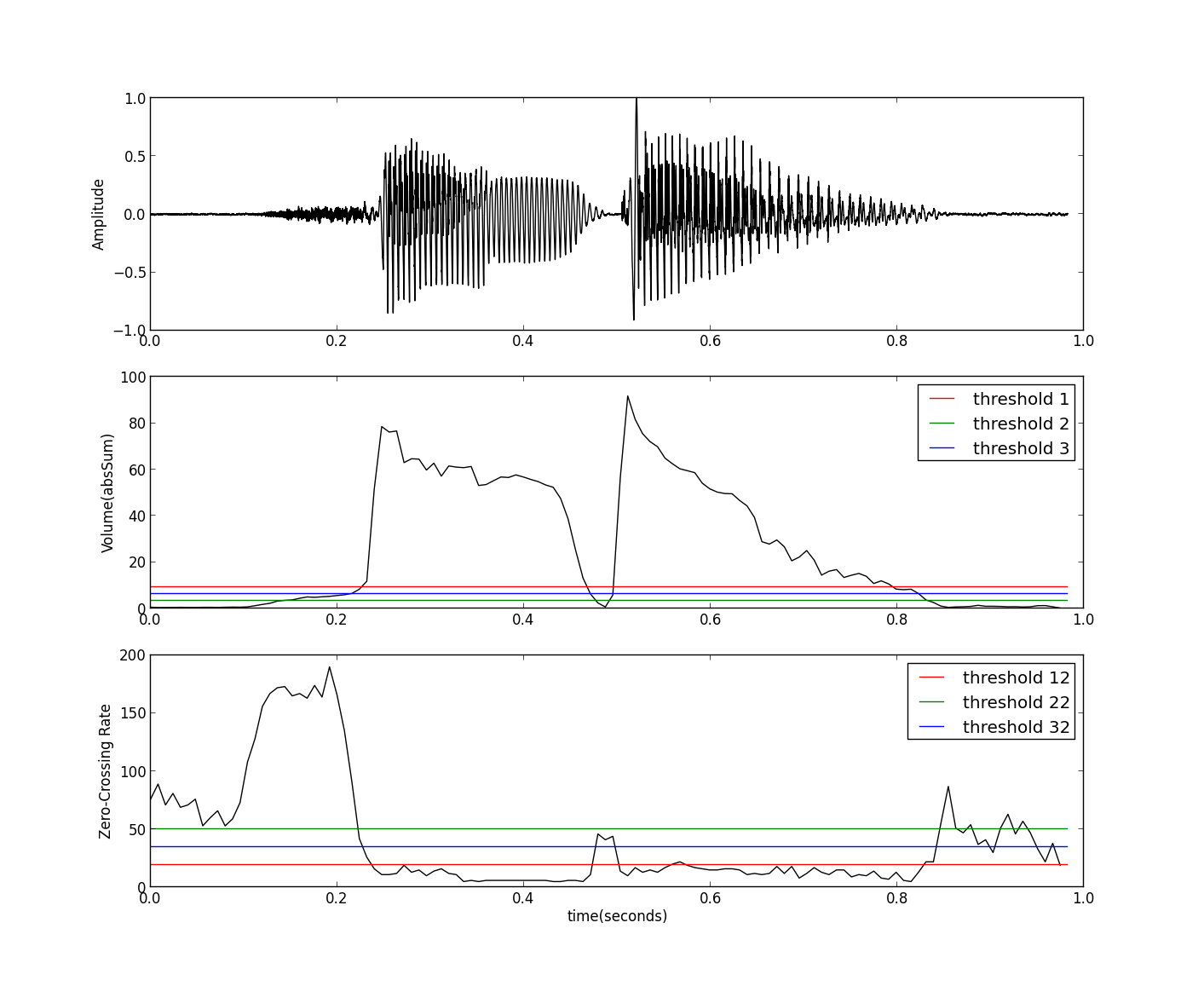
下面我们来看看最简单的、不需要训练的方法,其代码如下: ``` py3 import wave import numpy as np import matplotlib.pyplot as plt import Volume as vp def findIndex(vol,thres): l = len(vol) ii = 0 index = np.zeros(4,dtype=np.int16) for i in range(l-1): if((vol[i]-thres)*(vol[i+1]-thres)<0): index[ii]=i ii = ii+1 return index[[0,-1]] fw = wave.open('sunday.wav','r') params = fw.getparams() nchannels, sampwidth, framerate, nframes = params[:4] strData = fw.readframes(nframes) waveData = np.fromstring(strData, dtype=np.int16) waveData = waveData*1.0/max(abs(waveData)) # normalization fw.close() frameSize = 256 overLap = 128 vol = vp.calVolume(waveData,frameSize,overLap) threshold1 = max(vol)*0.10 threshold2 = min(vol)*10.0 threshold3 = max(vol)*0.05+min(vol)*5.0 time = np.arange(0,nframes) * (1.0/framerate) frame = np.arange(0,len(vol)) * (nframes*1.0/len(vol)/framerate) index1 = findIndex(vol,threshold1)*(nframes*1.0/len(vol)/framerate) index2 = findIndex(vol,threshold2)*(nframes*1.0/len(vol)/framerate) index3 = findIndex(vol,threshold3)*(nframes*1.0/len(vol)/framerate) end = nframes * (1.0/framerate) plt.subplot(211) plt.plot(time,waveData,color="black") plt.plot([index1,index1],[-1,1],'-r') plt.plot([index2,index2],[-1,1],'-g') plt.plot([index3,index3],[-1,1],'-b') plt.ylabel('Amplitude') plt.subplot(212) plt.plot(frame,vol,color="black") plt.plot([0,end],[threshold1,threshold1],'-r', label="threshold 1") plt.plot([0,end],[threshold2,threshold2],'-g', label="threshold 2") plt.plot([0,end],[threshold3,threshold3],'-b', label="threshold 3") plt.legend() plt.ylabel('Volume(absSum)') plt.xlabel('time(seconds)') plt.show() ``` 其中计算音量的函数calVolume参见 音量及其Python实现一文。程序的运行结果如下图:
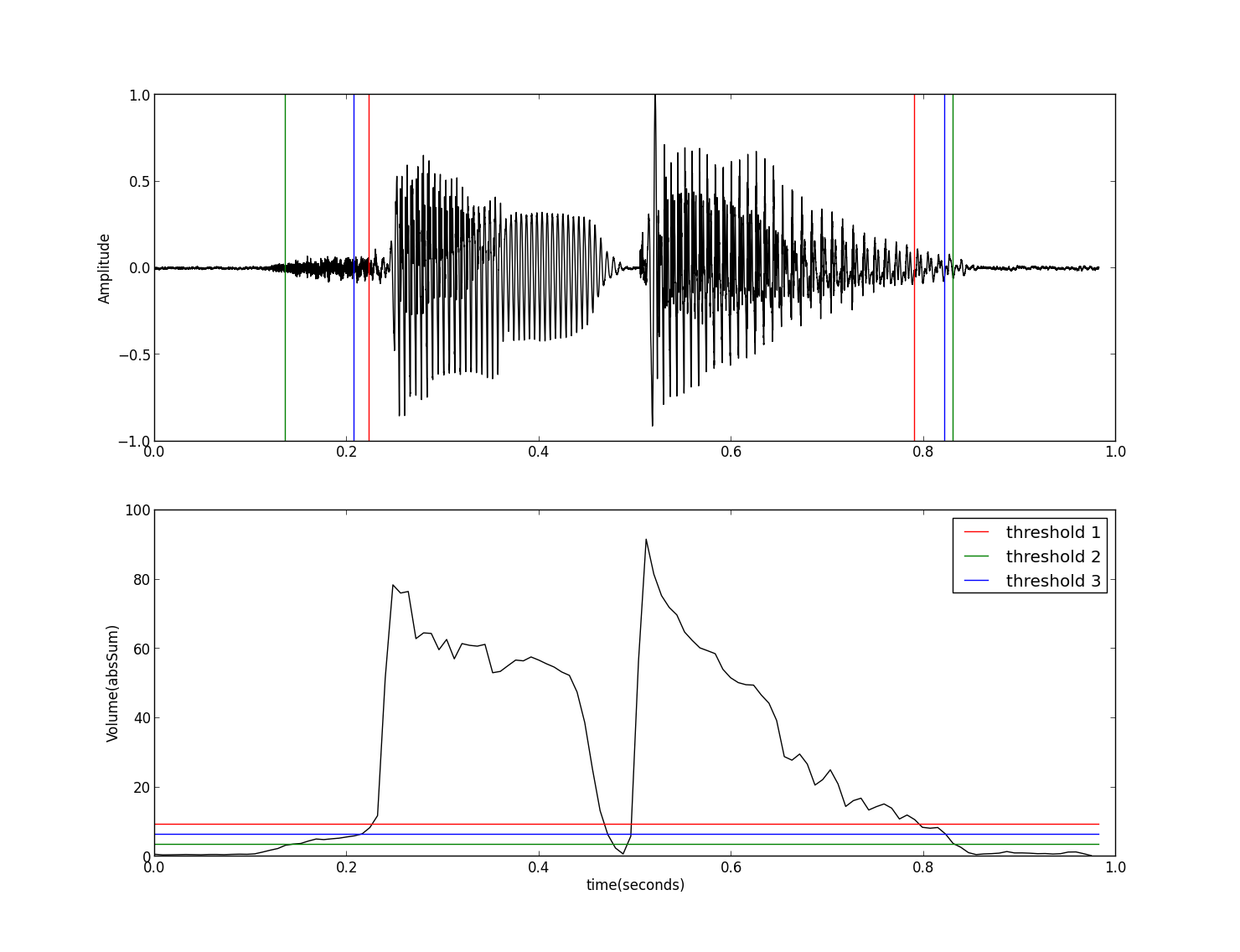
这里采用了三种设置阈值的方法,但这几种设置方法对所有的输入都是相同的,对于一些特定的语音数据可能得不到很好的结果,比如杂音较强、清音较多或音量 变化较大等语音信号,此时单一阈值的方法的效果就不太好了,虽然我们可以通过增加帧与帧之间的重叠部分,但相对而言计算量会比较大。下面我们利用一些更多的 特征来进行端点加测,例如使用过零率等信息,其过程如下: (1)以较高音量阈值($\tau _{u}$)为标准,找到初步的端点; (2)将端点前后延伸到低音量阈值($\tau _{l}$)处; (3)再将端点前后延伸到过零率阈值($\tau _{zc}$)处,以包含语音中清音的部分。 这种方法需要确定三个阈值($\tau _{u}$,$\tau _{l}$,$\tau _{zc}$),可以用各种搜寻方法来调整这三个参数。其示意图(参考[1])如下:
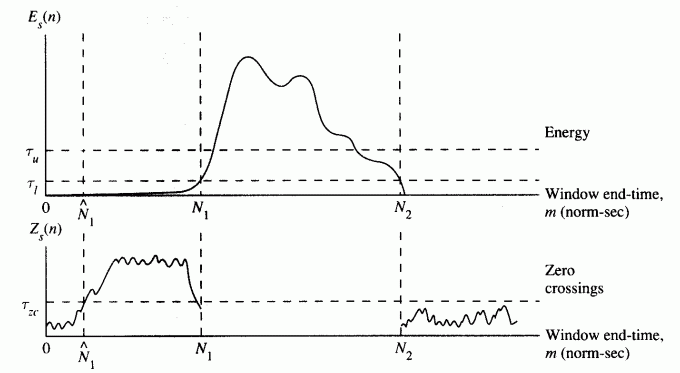
另外,我们还可以连续对波形进行微分,再计算音量,这样就可以凸显清音的部分,从而将其正确划分出来,详见参考[1]。
频域的端检方法
有声音的信号在频谱上会有重复的谐波结构,因此我们也可以使用频谱的变化性(Variation)或Entropy来进行端点检测,可以参见如下链接: http://neural.cs.nthu.edu.tw/jang/books/audiosignalprocessing/paper/endPointDetection/
总之,端点检测是语音预处理的重头戏,其实现方法也是五花八门,本文只给出了最简单最原始也最好理解的几种方法,这些方法要真正做到实用,还需要针对一些 特殊的情况在做一些精细的设置和处理,但对于一般的应用场景应该还是基本够用的。
参考(References)
[1]EPD in Time Domain: http://neural.cs.nthu.edu.tw/jang/books/audiosignalprocessing/epdTimeDomain.asp?title=6-2%20EPD%20in%20Time%20Domain [2]EPD in Frequency Domain: http://neural.cs.nthu.edu.tw/jang/books/audiosignalprocessing/epdFreqDomain.asp?title=6-3%20EPD%20in%20Frequency%20Domain