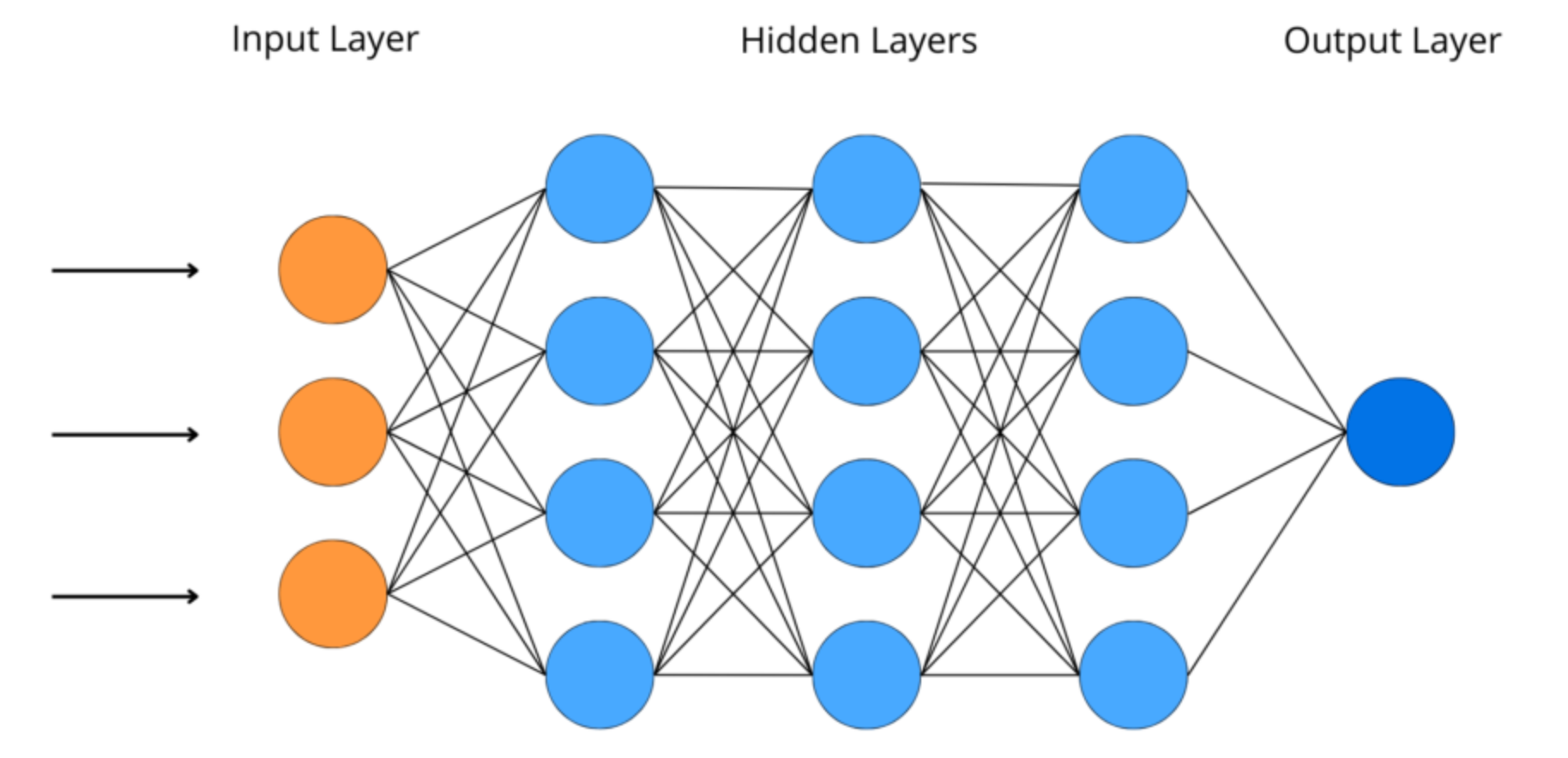
一、神经网络中隐层数和隐层节点数问题的讨论
1.1 隐层数
一般认为,增加隐层数可以降低网络误差(也有文献认为不一定能有效降低),提高精度,但也使网络复杂化,从而增加了网络的训练时间和出现“过拟合”的倾向。一般来讲应设计神经网络应优先考虑3层网络(即有1个隐层)。一般地,靠增加隐层节点数来获得较低的误差,其训练效果要比增加隐层数更容易实现。对于没有隐层的神经网络模型,实际上就是一个线性或非线性(取决于输出层采用线性或非线性转换函数型式)回归模型。因此,一般认为,应将不含隐层的网络模型归入回归分析中,技术已很成熟,没有必要在神经网络理论中再讨论之。
1.2 隐层节点数
在BP 网络中,隐层节点数的选择非常重要,它不仅对建立的神经网络模型的性能影响很大,而且是训练时出现“过拟合”的直接原因,但是目前理论上还没有一种科学的和普遍的确定方法。 目前多数文献中提出的确定隐层节点数的计算公式都是针对训练样本任意多的情况,而且多数是针对最不利的情况,一般工程实践中很难满足,不宜采用。事实上,各种计算公式得到的隐层节点数有时相差几倍甚至上百倍。为尽可能避免训练时出现“过拟合”现象,保证足够高的网络性能和泛化能力,确定隐层节点数的最基本原则是:在满足精度要求的前提下取尽可能紧凑的结构,即取尽可能少的隐层节点数。研究表明,隐层节点数不仅与输入/输出层的节点数有关,更与需解决的问题的复杂程度和转换函数的型式以及样本数据的特性等因素有关。
在确定隐层节点数时必须满足下列条件:
(1)隐层节点数必须小于N-1(其中N为训练样本数),否则,网络模型的系统误差与训练样本的特性无关而趋于零,即建立的网络模型没有泛化能力,也没有任何实用价值。同理可推得:输入层的节点数(变量数)必须小于N-1。
(2)训练样本数必须多于网络模型的连接权数,一般为2~10倍,否则,样本必须分成几部分并采用“轮流训练”的方法才可能得到可靠的神经网络模型。
总之,若隐层节点数太少,网络可能根本不能训练或网络性能很差;若隐层节点数太多,虽然可使网络的系统误差减小,但一方面使网络训练时间延长,另一方面,训练容易陷入局部极小点而得不到最优点,也是训练时出现“过拟合”的内在原因。因此,合理隐层节点数应在综合考虑网络结构复杂程度和误差大小的情况下用节点删除法和扩张法确定。
二、网络权重初始化
第i个隐层的初始权重应该随机均匀的分布在一个对称的区间,这个区间的长度与使用的激活函数有关。对于双曲正切函数tanh,论文Xavier10 中指出,该区间为
其中 nj 为第 (j-1) 层的节点数;而对于 sigmoid 函数,该区间为tanh区间的4倍。这样初始化,可以保证在训练的初期,每个神经元能够很好的使用激活函数进行前向和反向传播。
三、特征规整(数据归一化)
数据预处理中,标准的第一步是数据归一化。虽然这里有一系列可行的方法,但是这一步通常是根据数据的具体情况而明确选择的。特征归一化常用的方法包含如下几种:
简单缩放
逐样本均值消减(也称为移除直流分量)
特征标准化(使数据集中所有特征都具有零均值和单位方差)
3.1简单缩放
在简单缩放中,我们的目的是通过对数据的每一个维度的值进行重新调节(这些维度可能是相互独立的),使得最终的数据向量落在 [0,1]或[ − 1,1] 的区间内(根据数据情况而定)。这对后续的处理十分重要,因为很多默认参数(如 PCA-白化中的 epsilon)都假定数据已被缩放到合理区间。
例子:在处理自然图像时,我们获得的像素值在 [0,255] 区间中,常用的处理是将这些像素值除以255,使它们缩放到 [0,1] 中.
3.2 逐样本均值消减
如果你的数据是平稳的(即数据每一个维度的统计都服从相同分布),那么你可以考虑在每个样本上减去数据的统计平均值(逐样本计算)。
例子:对于图像,这种归一化可以移除图像的平均亮度值 (intensity)。很多情况下我们对图像的照度并不感兴趣,而更多地关注其内容,这时对每个数据点移除像素的均值是有意义的。注意:虽然该方法广泛地应用于图像,但在处理彩色图像时需要格外小心,具体来说,是因为不同色彩通道中的像素并不都存在平稳特性。
3.3 特征标准化
特征标准化指的是(独立地)使得数据的每一个维度具有零均值和单位方差。这是归一化中最常见的方法并被广泛地使用(例如,在使用支持向量机(SVM)时,特征标准化常被建议用作预处理的一部分)。在实际应用中,特征标准化的具体做法是:首先计算每一个维度上数据的均值(使用全体数据计算),之后在每一个维度上都减去该均值。下一步便是在数据的每一维度上除以该维度上数据的标准差。
例子:处理音频数据时,常用 Mel 倒频系数 MFCCs 来表征数据。然而MFCC特征的第一个分量(表示直流分量)数值太大,常常会掩盖其他分量。这种情况下,为了平衡各个分量的影响,通常对特征的每个分量独立地使用标准化处理。
四、训练参数
4.1 学习率与优化器
学习率(learning rate):决定权重更新幅度。初始可设为 0.1 或 0.001,并在训练中逐步衰减(如每隔若干 epoch 乘以 0.5)。
优化器:可选 SGD、Adam 等,Adam 对大多数任务收敛较快且稳定。
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, weight_decay=0.005)
4.2 批大小与迭代次数
批大小(batch size): 影响显存占用与梯度估计稳定性。小批量(如 32、64)适合内存有限场景,大批量可加快训练但需调整学习率。
迭代次数(epochs): 训练至验证集性能不再提升即可,避免过拟合。