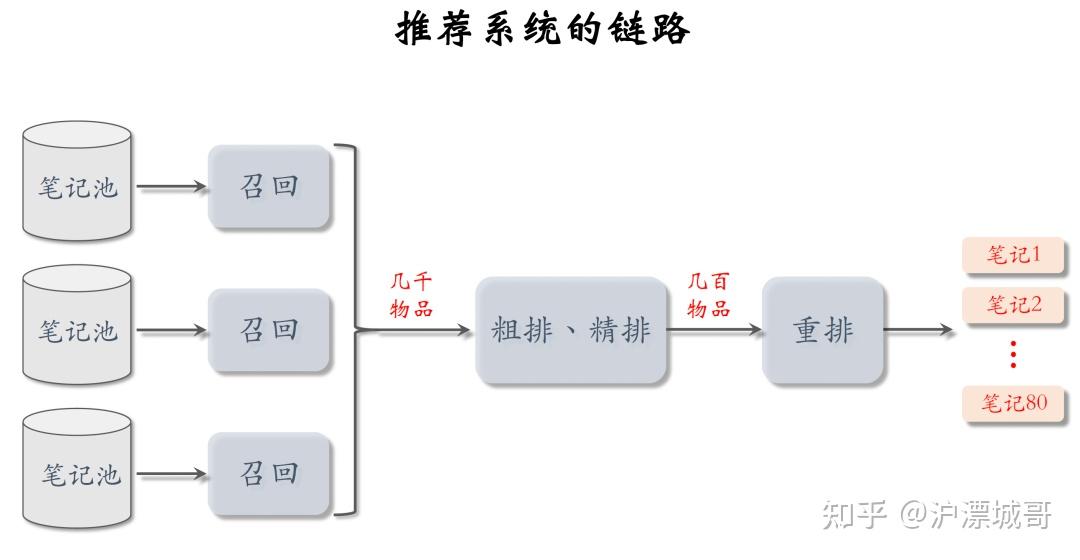
原文链接:https://zhuanlan.zhihu.com/p/701181424
大家好,我是凉夏同学。今天是我第一次在知乎分享我对算法模型的理解,有些生疏,还请大家多多指教。感兴趣的话,敬请关注公众号:凉夏的机器学习笔记。感恩~
今天要讲的是最近比较火的一种网络结构,可以近乎“无脑地”加入到网络结构当中,基本上都可以带来或多或少的效果提升。这个网络结构有人叫他门控网络、门控结构,也有人叫他的英文名“gating”,也有人叫他动态权重。
这篇文章,我会先讲一下我对门控机制的理解,然后会简单介绍几个使用门控机制的论文。
门控的本质
一直都觉得深度学习模型架构里,很多东西都是相同的,虽然很多时候他们有不同的名称、亦或是用在了不同的模型位置,但底层的思想和逻辑很可能是一致的。而我认为,门控网络结构的本质就是注意力机制。说到注意力机制,大家应该都不陌生,该结构出现在以DNN模型为基础的各种应用结构中,例如:transformer里面使用了multi-head attention(MHA)这种多头自注意力机制;用户行为序列建模DIN结构使用了target attention结构。