一、下一代大数据计算引擎
自从数据处理需求超过了传统数据库能有效处理的数据量之后,Hadoop 等各种基于 MapReduce 的海量数据处理系统应运而生。从 2004 年 Google 发表 MapReduce 论文开始,经过近 10 年的发展,基于 Hadoop 开源生态或者其它相应系统的海量数据处理已经成为业界的基本需求。
但是,很多机构在开发自己的数据处理系统时都会发现需要面临一系列的问题。从数据中获取价值需要的投入远远超过预期。常见的问题包括:
- 非常陡峭的学习曲线。刚接触这个领域的人经常会被需要学习的技术的数量砸晕。不像经过几十年发展的数据库一个系统可以解决大部分数据处理需求, Hadoop 等大数据生态里的一个系统往往在一些数据处理场景上比较擅长,另一些场景凑合能用,还有一些场景完全无法满足需求。结果就是需要好几个系统来处理不同的场景。
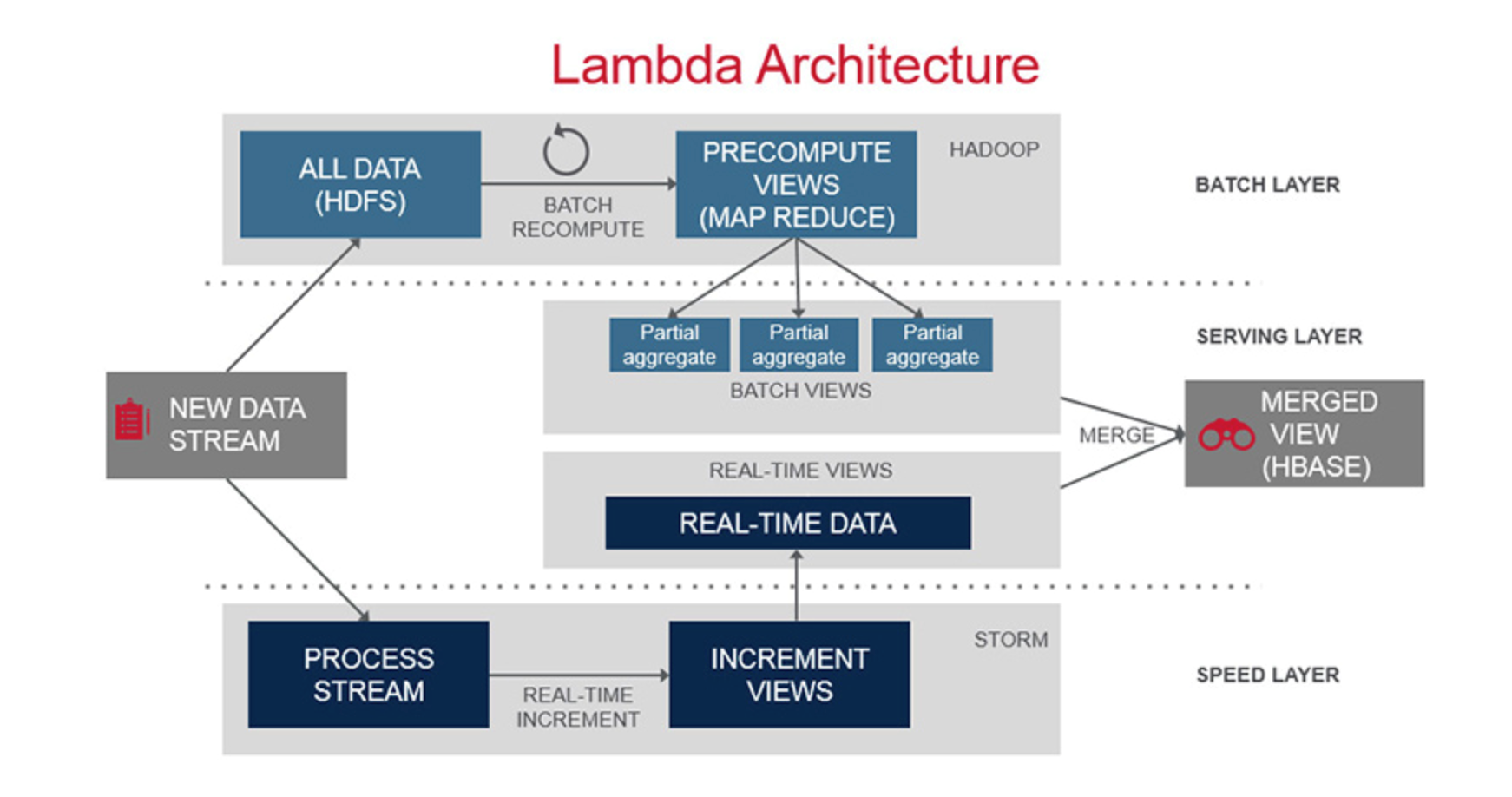
(来源: https://mapr.com/developercentral/lambda-architecture/ )