本文介绍如何使用Windows API来录制语音信号兵保存到wave文件中,主要用到三个结构体和几个wave开头的API函数(在Winmm.lib文件中)。其中三个结构体是WAVEFORMATEX、WAVEHDR、MMTIME,其详细定义都在MMSystem.h中定义, 可以转到定义看其详细内容及每一项的英文注释。用到的API函数的详细用法可以参见MSDN: http://msdn.microsoft.com/en-us/library/windows/desktop/dd743847(v=vs.85).aspx 详细的使用过程请看下文的源代码,这是一个Win32 Application,需要手动添加Winmm.lib的依赖。
语音信号处理之时域分析-音高追踪及其Python实现
1.概述
在音高及其Python实现一文 中,我们使用了简单的“观察法”来计算音高,这并不太难,但这并不有好而且费时费力,那么我们就想,如何通过分析和计算,使用算法来自动计算音高呢? 用算法让计算机自动抓取音高的过程,称为音高追踪(Pitch Tracking)。所得到的音高信息有如下一些应用: ·旋律识别(Melody Recognition):或称为“哼唱选歌”,也就是如何由使用者的哼唱,找出音乐资料库中间对应的歌。 ·汉语声调识别(Tone Recognition):辨识使用者讲一句话时,每一个字的声调(一声、二声、三声、四声等)。 ·语音合成韵律分析(Prosody Analysis)中的音高分析:如何在合成语音时,使用最自然的音高曲线。 ·语音评分中的音调评分(Intonation Assessment):如何评估使用者说话的语音,其音高曲线是否标准。 ·语音识别(Speech Recognition):我们可以使用语句的音高来提高语音辨识的正确率。 总而言之,音高追踪是语音信号处理中最基本也最重要的一个环节之一。
2.音高追踪的基本流程
音高追踪的基本流程如下: (1)将整段音讯讯号切成音框(Frames),相邻音框之间可以重叠。 (2)算出每个音框所对应的音高。 (3)排除不稳定的音高值。(可由音量来筛选,或由音高值的范围来过滤。) (4)对整段音高进行平滑化,通常是使用「中位数滤波器」(Median Filters)。
大白鼠听人话
最近一直忙着准备给媒体展示的音控大鼠机器人一不小心上了CCTV了,虽然自己感觉没什么了不起的,也不知道网络上是什么评论。 但既然上了CCTV,还是发博纪念一下吧
央视新闻视频链接:浙江杭州最新科研成果:大白鼠听人话 真没想到自己居然正面出境这么长时间。
杭州日报的记者写的新闻还挺生动的:“嫁接”了机器视觉的大白鼠在沙盘迷宫中寻觅阿汤哥的照片
PS:感谢CCTV,感谢杭州日报,感谢ZJU,感谢CCNT,感谢各位老师和同学,感谢生仪的给大鼠做开颅手术的两位mm,感谢各位在微博帮忙宣传和转发的各位同学!
语音信号处理之时域分析-端点检测及Python实现
端点检测
端点检测(End-Point Detection,EPD)的目标是要决定信号的语音开始和结束的位置,所以又可以称为Speech Detection或Voice Activity Detection(VAD)。 端点检测在语音预处理中扮演着一个非常重要的角色。
常见的端点检测方法大致可以分为如下两类: (1)时域(Time Domain)的方法:计算量比较小,因此比较容易移植到计算能力较差的嵌入式平台 (a)音量:只使用音量来进行端检,是最简单的方法,但是容易对清音造成误判。另外,不同的音量计算方法得到的结果也不尽相同,至于那种方法更好也没有定论。 (b)音量和过零率:以音量为主,过零率为辅,可以对清音进行较精密的检测。 (2)频域(Frequency Domain)的方法:计算量相对较大。 (a)频谱的变化性(Variance):有声音的频谱变化较规律,可以作为一个判断标准。 (b)频谱的Entropy:有规律的频谱的Entropy一般较小,这也可以作为一个端检的判断标准。
下面我们分别从这两个方面来探讨端检的具体方法和过程。
语音信号处理之时域分析-音色及其Python实现
音色(Timbre)
音色是一个很模糊的概念,它泛指语音的内容,例如“天书”这两个字的发音,虽然都是一声(即他们的音高应该是相同或接近的), 但由于音色不同,我们可以分辨这两个音。直觉而言,音色的不同,意味着基本波形的不同,因此我们可以用基本周期的波形来代表音色。
若要从基本周期的波形来直接分析音色是一件很困难的事情。通常我们的做法是将每一个帧进行频谱分析(Spectral Analysis),算出一个 帧如何分解为不同频率的分量,然后才能进行对比或分析。在频谱分析中,最常用的方法就是快速傅里叶变换(Fast Fourier Transform,FFT), 这是一个相当常用的方法,可以讲在时域(Time Domain)的信号转换成频域(Frequency Domain)的信号,并进而知道每个频率的信号强度。
语谱图(Spectrogram)就是语音频谱图,一般是通过处理接收的时域信号得到频谱图,因此只要有足够时间长度的时域信号就可以(时间长度 为保证频率分辨率)。专业点讲,语谱图就是频谱分析视图,如果针对语音数据的话,叫语谱图。语谱图的横坐标是时间,纵坐标是频率,坐标点 值为语音数据能量,因而语谱图很好的表达了语音的音色随时间变化的趋势。有些经验丰富的人能够通过看语谱图而知道对应的语音信号的内容, 这种技术成为Spectrogram Reading。
语音信号处理之时域分析-音高及其Python实现
音高(Pitch)
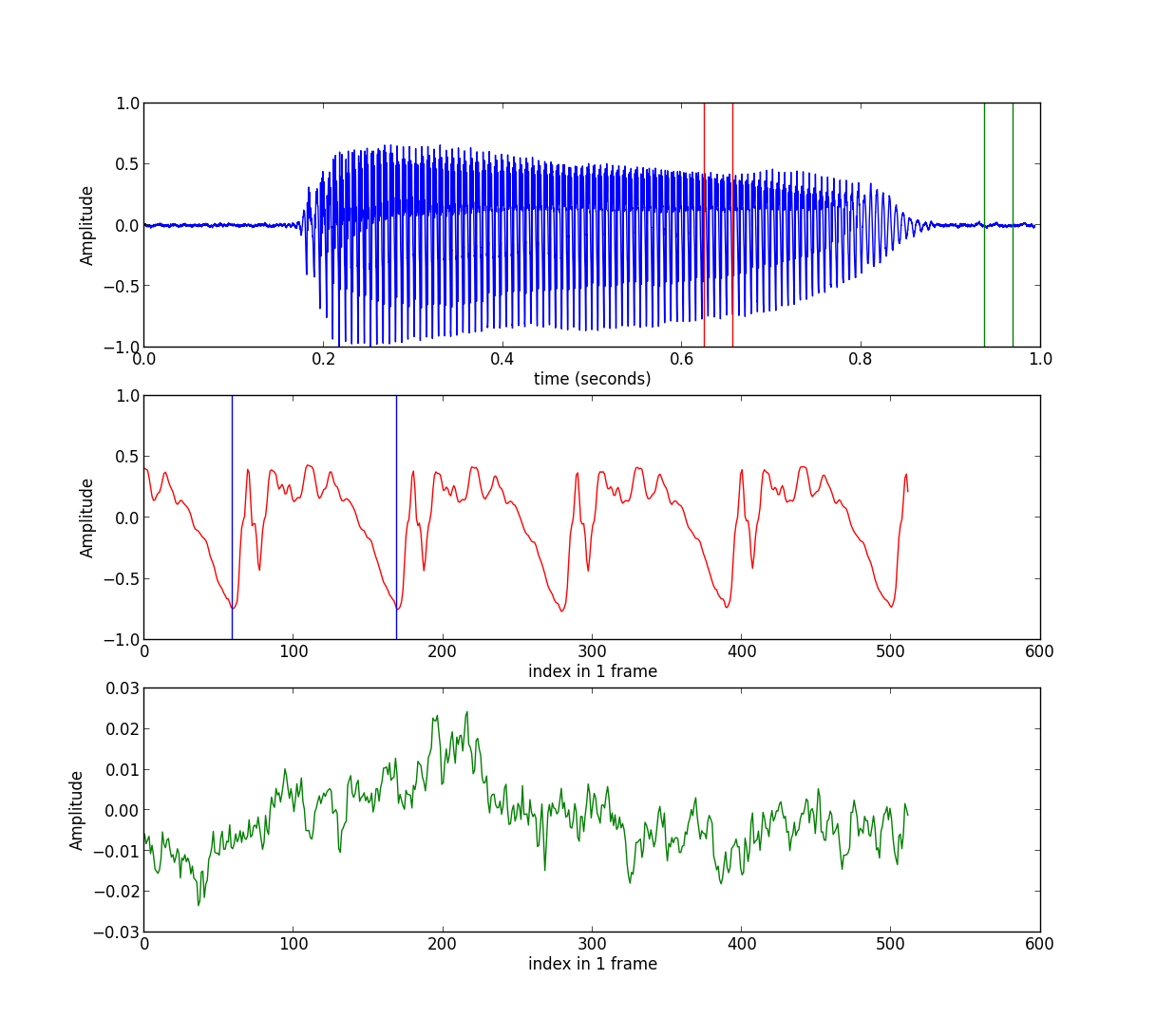
概念:音高(Pitch)是语音信号的一个很重要的特征,直觉上而言它表示声音频率的高低,这个频率是指基本频率(基频),也即基本周期的倒数。 若直接观察语音的波形,只要语音信号稳定,我们可以很容易的看出基本周期的存在。例如我们取一个包含256个采样点的帧,单独绘制波形图,就可以明显的 看到它的基本周期。如下图所示:
语音信号处理之时域分析-过零率及其Python实现
过零率(Zero Crossing Rate)
概念:过零率(Zero Crossing Rate,ZCR)是指在每帧中,语音信号通过零点(从正变为负或从负变为正)的次数。 这个特征已在语音识别和音乐信息检索领域得到广泛使用,是对敲击的声音的分类的关键特征。
ZCR的数学形式化定义为:
特性: (1).一般而言,清音(unvoiced sound)和环境噪音的ZCR都大于浊音(voiced sound); (2).由于清音和环境噪音的ZCR大小相近,因而不能够通过ZCR来区分它们; (3).在实际当中,过零率经常与短时能量特性相结合来进行端点检测,尤其是ZCR用来检测清音的起止点; (4).有时也可以用ZCR来进行粗略的基频估算,但这是非常不可靠的,除非有后续的修正(refine)处理过程。
语音信号处理之时域分析-音量及其Python实现
1.概述(Introduction)
本系列文主要介绍语音信号时域的4个基本特征及其Python实现,这4个基本特征是: (1)音量(Volume); (2)过零率(Zero-Crossing-Rate); (3)音高(Pitch); (4)音色(Timbre)。
2.音量(Volume)
音量代表声音的强度,可由一个窗口或一帧内信号振幅的大小来衡量,一般有两种度量方法: (1)每个帧的振幅的绝对值的总和:
语音信号处理基础学习笔记之时域处理
语音信号的分析分为时域、频域、倒谱域等,时域分析简单、运算量小、物理意义明确,但对于语音识别而言, 更为有效的是频域的分析方法,那么为什么还有进行时域的分析呢?
语音信号具有时变特性,但在短时内可以看做是平稳的,所以语音的时域分析是建立在“短时”的条件下的,经研究统计, 语音信号在帧长为10ms~30ms内是相对平稳的。
语音信号是模拟信号,在进行处理之前,要进行数字化,模拟信号数字化的一般方法是采样,按照Nyquist采样定理进行 采样(一般在8K~10KHz)后,在进行量化(一般用8bit,也有16bit等)和编码,变为数字信号。
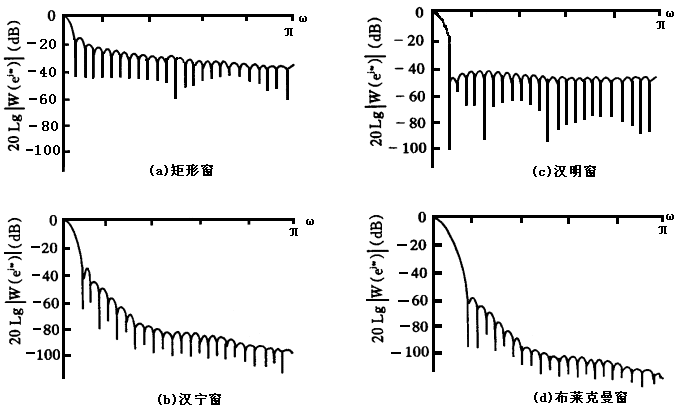
在语音信号数字化之后,就可以开始对其进行处理了,首先是预处理,由于语音信号的平均功率谱受声门激励和口鼻辐射的影响, 高频端大约在800Hz以上按6dB/倍频程跌落,为此要在预处理中进行预加重。预加重的目的是提升高频部分,是信号变得平坦, 以便于进行频谱分析或声道参数分析。预加重可以用具有6dB/倍频程的提升高频特性的预加重数字滤波器实现。预处理的另一 方面工作是分帧和加窗:分帧的帧长一般在10ms~30ms,分帧既可以是连续的,也可以是有部分over-lap;短时分析的实质是 对信号加窗,一般采用Hamming窗,其他的还有矩形窗、汉宁窗等,如下图所示。
五一登高远足
五一天晴气爽,登高望远,强身健体!只可惜“不畏浮云遮望眼,只缘身在最高层” 这句诗在空气严重污染的今天已不适用了!
